")
")
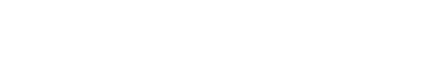
CATMA - გზამკვლევი დამწყებთათვის
CATMA - Computer Assisted Text Markup and Analysis - არის ტექსტის ანოტირებისა და ანალიზის დიგიტალური პლატფორმა.
- რას გვთავაზობს CATMA?
- CATMA-ში ვტვირთავთ სასურველ ტექსტს;
- ვქმნით მარკერებს/თეგებს, რომლითაც ტექსტის ანოტირება გვსურს;
მარკერებს თავად ვარქმევთ სახელს და ვანიჭებთ სასურველ ფერს. - ვახდენთ ტექსტის ანოტირებას;
გარდა ანოტირებისა, მუშაობის პროცესში ტექსტს, შესაძლოა, დავურთოთ კომენტარები; - ვაანალიზებთ მონაცემებს;
- ვახდენთ მონაცემების ვიზუალიზებას;
- სურვილისამებრ, სამუშაო პროცესის დაწეყებამდე ან მის შემდეგ, ჩვენს დოკუმენტს ვუზიარებთ კოლეგებს, რომლებსაც ტექსტის ანოტირებისა და კომენტარების დართვის უფლებას ვანიჭებთ. ე.ი. CATMA მოსახერხებელია კოლაბორაციული მუშაობისთვის.
CATMA-ს სამუშაო სივრცე ასე გამოიყურება:
მარცხნივ განთავსებულია ტექსტი, ხოლო მარჯვნივ ჩანს მარკერები, რომელიც ჩვენ მიერ არის შექმნილი ტექსტის ანოტირებისთვის.
- რატომ CATMA?
CATMA-ს მთავარი უპირატესობა სიმარტივე და არადოგმატიზმია.
სხვა ედიტორებისგან განსხვავებით (მაგ.Oxygen), ამ პლატფორმის გამოყენება და მის მიერ შემოთავაზებული ინსტრუმენტების ათვისება შესაძლებელია სპეციალური ცოდნის გარეშე.
სხვა ედითორებთან შედარებით სიმარტივეს ის განაპირობებს, რომ CATMA-ში ტექსტის ანოტირება მაქსიმალურად ჰგავს ფიზიკურ წიგნში ხელით მუშაობას, ის ტრადიციული ფილოლოგიური სამუშაო პროცესის მოდელზეა დაფუძნებული.
ანოტირების პროცესი ორივე შემთხვევაში მსგავსია: როგორც ტრადიციული კვლევებისთვის წიგნში სხვადასხვა ფერის ფანქრით ინიშნავდნენ განსხვავებულ ინფორმაციას, ასევეა კატმაშიც.
თუმცა კატმა მხოლოდ სასურველი ტექსტობრივი მონაცემის მონიშვნას არ სჯერდება, ანოტირების გარდა კატმაში მარკირებული ინფორმაცია მზადაა კვლევის შემდეგი ეტაპების გასავლელად: რაოდენობრივი მანქანური ანალიზისთვისა და მონაცემების ვიზუალიცაზიისთვის, რაც შეუძლებელია დიგიტალური პლატფორმის გამოყენების გარეშე.
- რა ტიპის ინფორმაციის მონიშვნა/ ანოტირება არის შესაძლებელი?
CATMA-ში, კვლევის მიზნის შესაბამისად, შეიძლება მოინიშნოს ნებისმიერი ტიპის ინფორმაცია მკვლევრის მიერ შექმნილი მარკერების/თეგების საშუალებით.
CATMA არ გვთავაზობს უკვე არსებული, შეზღუდული რაოდენობის მარკერები/თეგების გამოყენებას, მკვლევარმა თავად უნდა შექმნას მარკერები მისი ინდივიდუალური მიზნის შესაბამისად.
მაგალითად, წარმოვიდგინოთ, რომ მკვლევრის მიზანია მოდერნისტულ რომანში ცნობიერების განსახოვნების ფორმების ანალიზი.
ამ მიზნისთვის მკვლევარი კვლევის პირველ ეტაპზე განსაზღვრავს ცნობიერების რომელი ფორმებია მისთვის საინტერესო, მაგალითად: პირდაპირი ფიქრი, ირიბი ფიქრი …
კატმაში ცნობიერების ამ ფორმების ანოტირებისთვის მკლევარი თავად შექმნის მარკერებს (“თეგებს” ), რომელსაც დაარქმევს შესაბამის სახელებს: პირდაპირი ფიქრი, ირიბი ფიქრი …
ე.ი. მკვლევარი თავად ირჩევს რისი მონიშვნა უნდა და თავად ქმნის მოსანიშნ საშუალებას - სახელდებულ მარკერს.
რეგისტრაცია და სამუშაო პროცესი
იმისთვის, რომ შევძლოთ CATMA-ს გამოყენება, უნდა ვეწვიოთ ოფიციალურ საიტს: https://catma.de/
საიტის საწყისი/Home გვერდი ასე გამოიყურება:

CATMA-ს ინსტრუმენტების გამოსაყენებლად, საჭიროა გადავიდეთ ლურჯად მონიშნულ ოფციაზე “Work with CATMA”.
ამის შემდეგ გამოჩნდება ასეთი გვერდი:

CATMA-ში შესასვლელად ორი ვარიანტი არსებობს:
- Sign In ოფცია უნდა გამოვიყენოთ მაშინ, თუკი სპეციალური რეგისტრაციის გარეშე გვსურს პლატფორმის გამოყენება ჩვენი მეილის საშუალებით.
აქაც დაგვხვდება ორი ვარიანტი (Photo N4):
Option 1, სადაც შესაძელებლია შესაბამის გრაფაში ჩავწეროთ ჩვენი მეილი და პაროლი.
Option 2, რომელიც შესაძლებელია გამოვიყენოთ იმ შემთხვევაში, თუკი Google-ს მეილით გვსურს წვდომის მოპოვება.
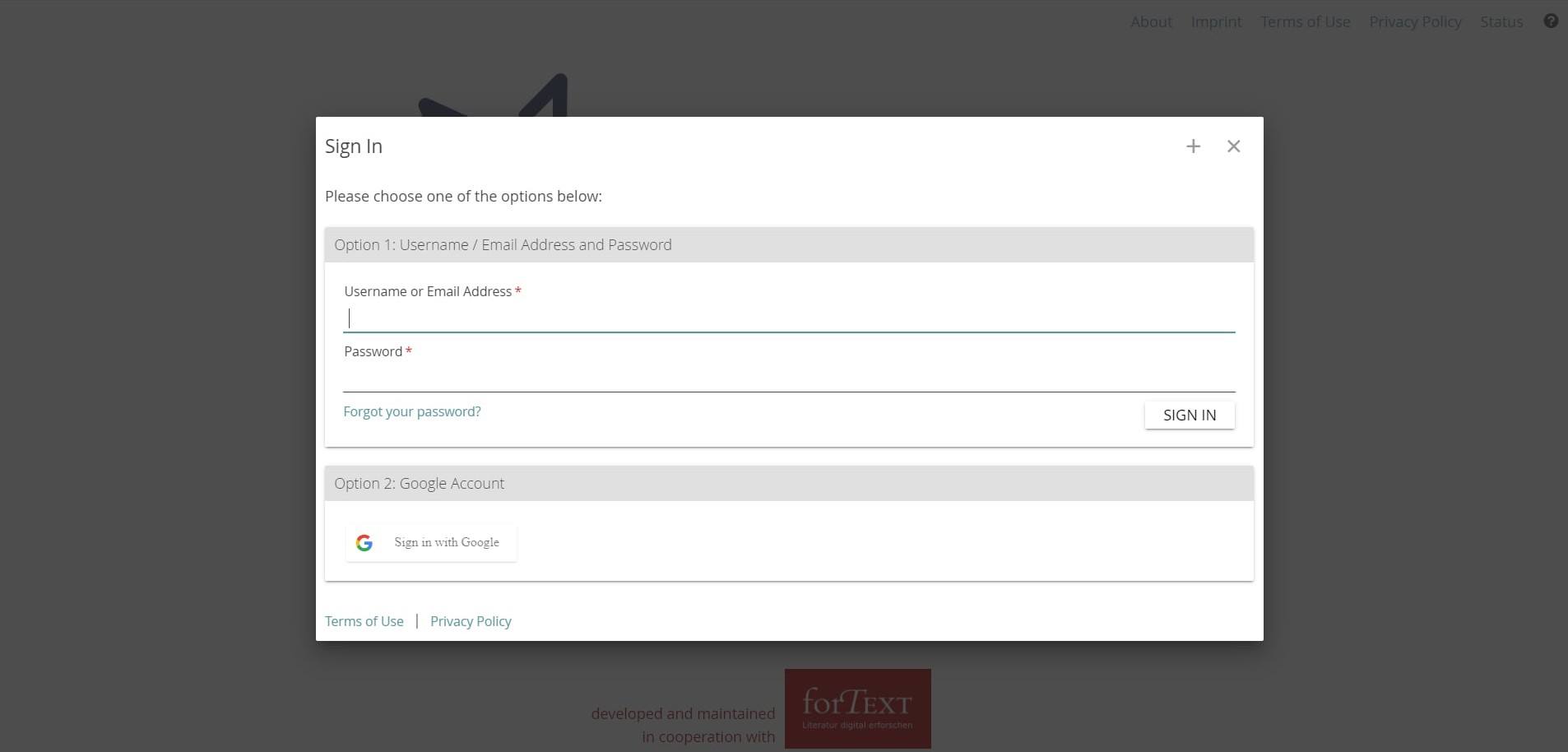
Photo N4 - Sign Up ოფციის ფანჯარა - Sign Up ოფცია უნდა გამოვიყენოთ მაშინ, თუკი გვსურს საიტზე დარეგისტრირება.
მსგავსად Sign In ოფციაში შესვლისა, აქაც ორი ვარინატი დაგვხვდება, სადაც შესაძლებელი იქნება ჩვენი მეილის მონაცემების შეყვანა ან Google-ის მეილით შესვლა.
მონაცემის შევსების შემდეგ მეილზე გამოიგზავნება ვერიფიკაციის კოდი; დადასტურების შემდეგ შესაძლებელი იქნება დაასრულოთ თქვენი პროფილის შექმნა: შეარჩიოთ სახელი და პაროლი საიტზე შესასვლელად.
რეგისტრაციის დასრულების შემდეგ გადავალთ სამუშაო სივრცეში, რომელიც ასე გამოიყურება:
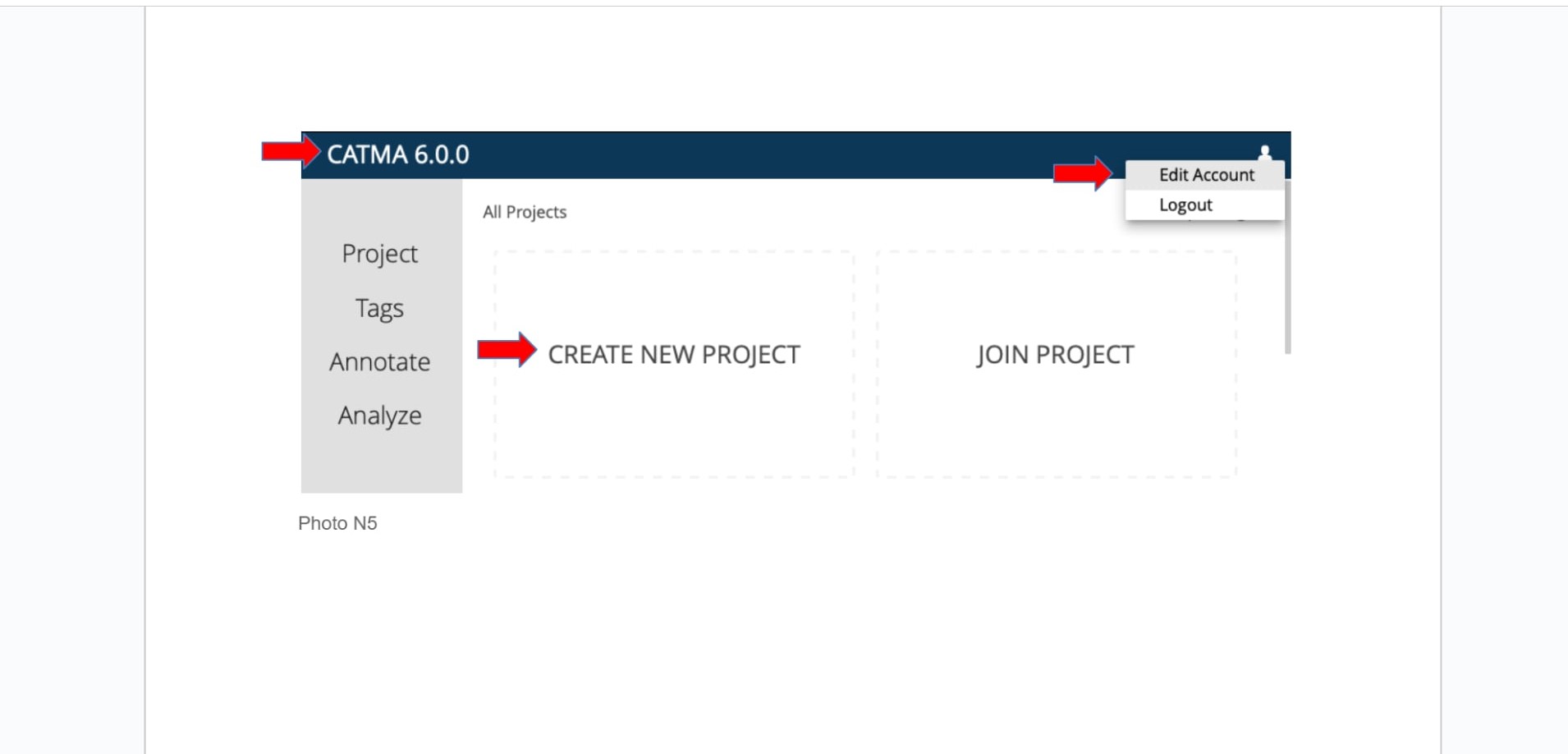
მარცხნივ, ლურჯ ჰორიზონტალურ ველში ასახულია CATMA-ს ვერსია; ვინაიდან საიტზე პერიოდულად მიმდინარეობს განახლება, ვერსიებიც, შესაბამისად, იცვლება.
ფოტოზე ასახული არის ვერსია CATMA 6.0.0. ამ ეტაპზე უკანასკნელი ვერსია არის CATMA 7.0.4
მარჯვნივ ზედა კუთხეში არსებული ოფციით შესაძლებელია ექაუნთის/ანგარიშის ცვლილება (Edit Account) და სისტემიად გასვლა (Logout).
მარცხნივ, ნაცრისფერი ველი, არის სანავიგაციო სივრცე. აქ ჩანს სამუშაო მოდულების ჩამონათვალი:
- Project
- Tags
- Annotate
- Analyze
ეს ჩამონათვალი ადგილზეა ნებისმიერ მოდულზე გადასვლისას.
ახალი პროექტის შესაქმნელად უნდა ავირჩიოთ ოფცია: “CREATE NEW PROJECT”.
ხოლო თუ გვსურს უკვე არსებულ პროექტზე წვდომის მიღება : “Join Project”; პროექტზე წვდომის მოსაპოვებლად საჭირო იქნება კოდი, რომელიც პროექტის მენეჯერმა უნდა გაგიზიაროთ.
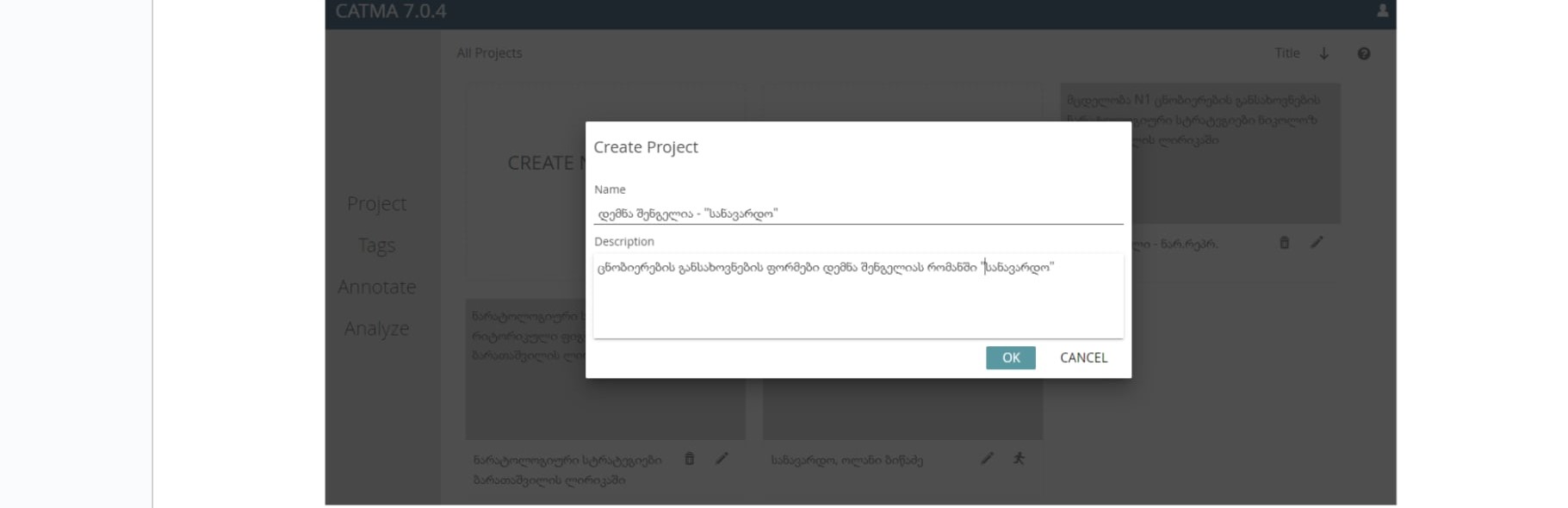
“Create New Project-ის” არჩევის შემდეგ კი გამოჩნდება ფანჯარა, რომელშიც შესაბამის ველში უნდა ჩავწეროთ პროექტის სახელი და აღწერა; ეს ფანჯარა ასე გამოიყურება:
მას შემდეგ, რაც შევქმნით პროექტს, საჭირო არის ავტვირთოთ ტექსტი ანოტირებისთვის.
შესაბამის ფანჯარაში (Photo N7) ჩანს ორი გრაფა:
DOCUMENTS & ANNOTATIONS და TAGSETS.
ტექსტის ასატვირთად პირველი გრაფის მარჯვნივ მოცემულ “+” ღილაკს ვირჩევთ.
შესაბამისი ფანჯარა ასე გამოიყურება:
+ ღილაკის არჩევის შემდეგ, უნდა ავირჩიოთ ოფცია “Add Document”.
ამის შემდეგ გამოჩნდება ასეთი ფანჯარა:
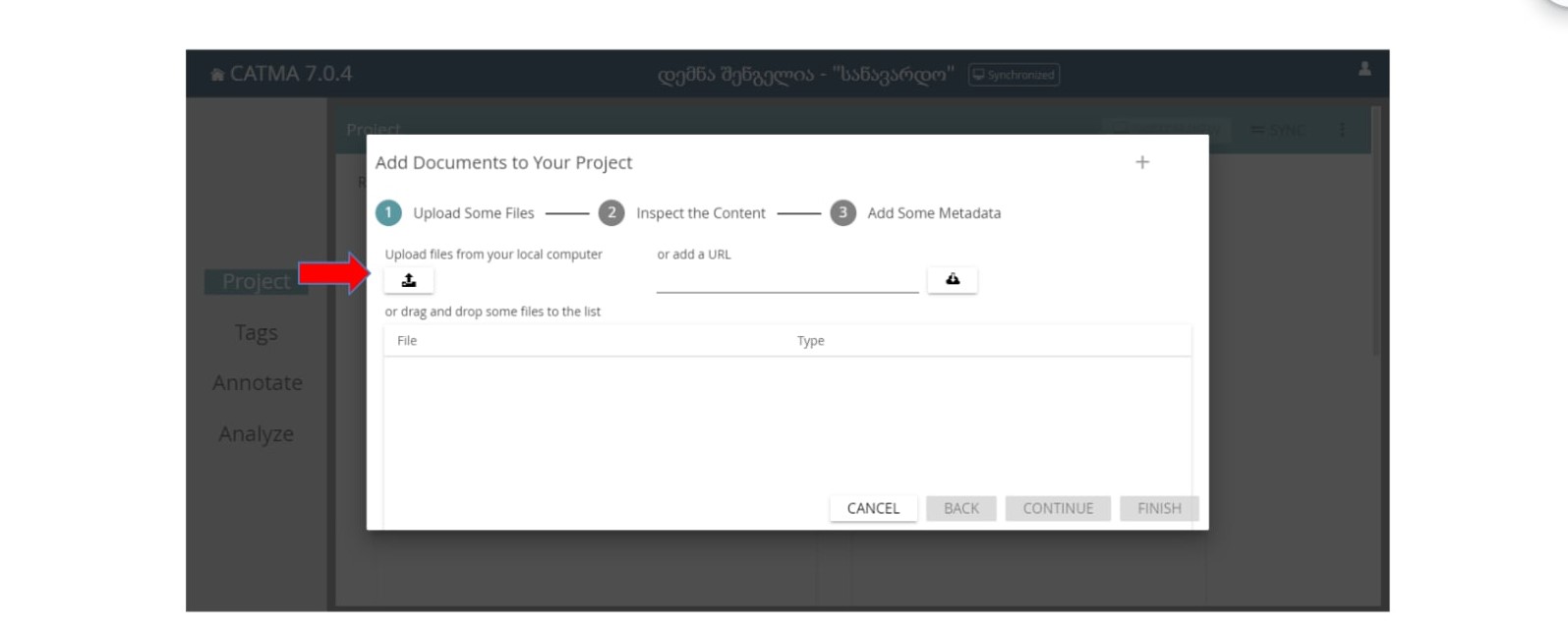
დოკუმენტის ატვირთვა შესაძლებელია როგორც ლეპტოპიდან (ისრის დაწკაპუნებით და ლეპტოპიდან შესაბამისი ფაილის შერჩევით), ასევე URL-ის მითითებითაც.
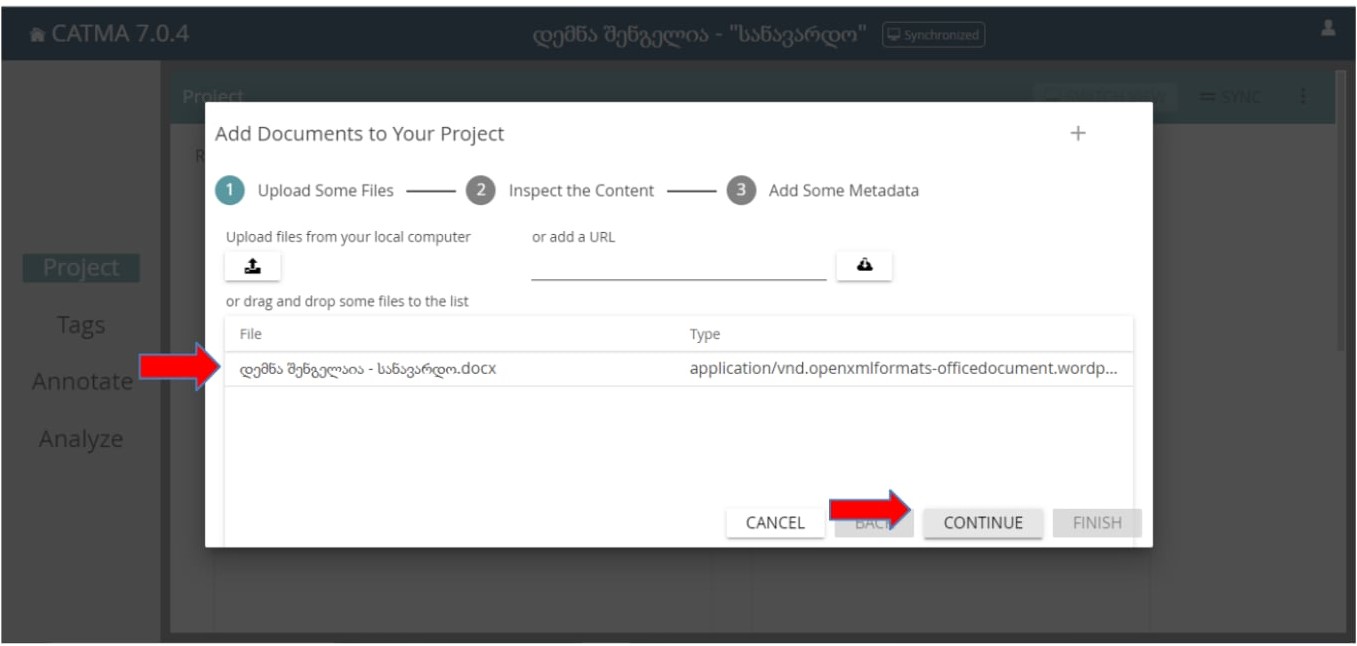
მას შემდეგ, რაც ავტვირთავთ დოკუმენტს, ის გამოჩნდება “File” გრაფაში და შესაძლებელი იქნება შემდეგ - მეორე ეტაპზე - გადასვლა, რისთვისაც ვირჩევთ “Continue”-ს (ფოტო N9).
მეორე ეტაპზე, მარჯევნა კუთხეში ნახავთ, წაიკითხავს თუ არა პროგრამა თქვენს ტექსტს ე.ი. მოახდენს თუ არა თქვენი დოკუმენტის ენის იდენტიფიცირებას:
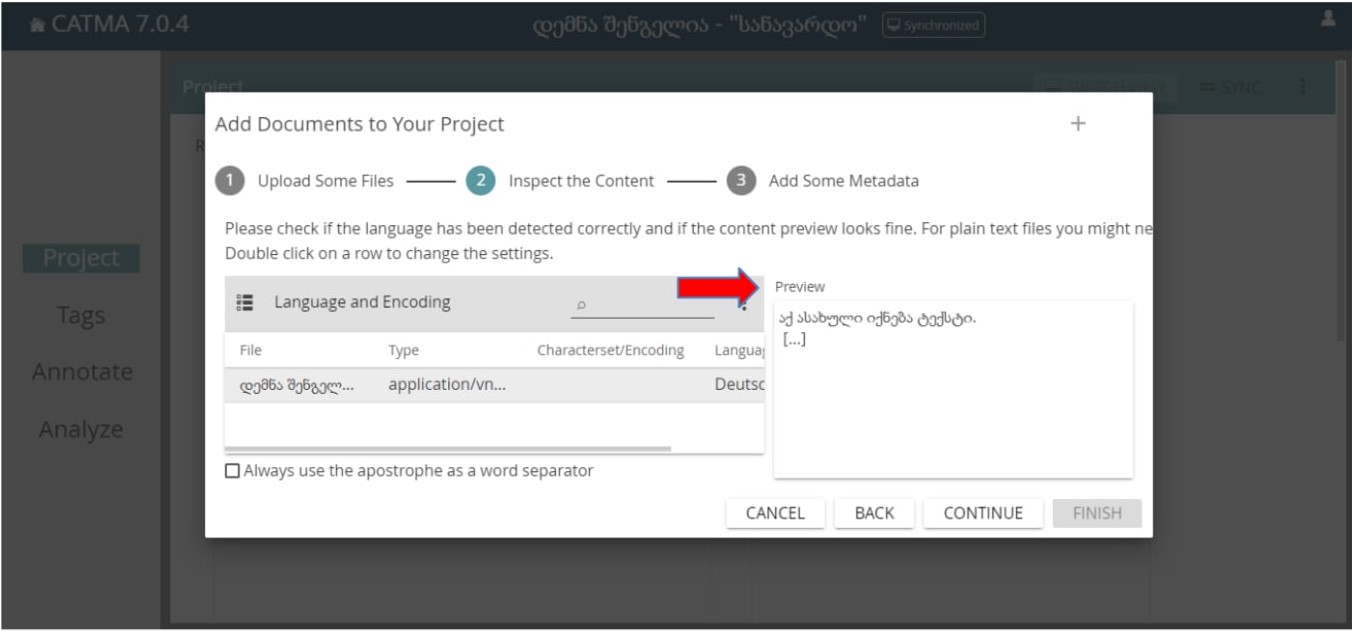
N10 ფოტოზე Preview გრაფაში ჩანს, რომ შერჩეული ტექსტი იკითხება, ამიტომ შესაძლებელია გადავიდეთ მესამე ეტაპზე “Continue” ოფციის საშუალებით.
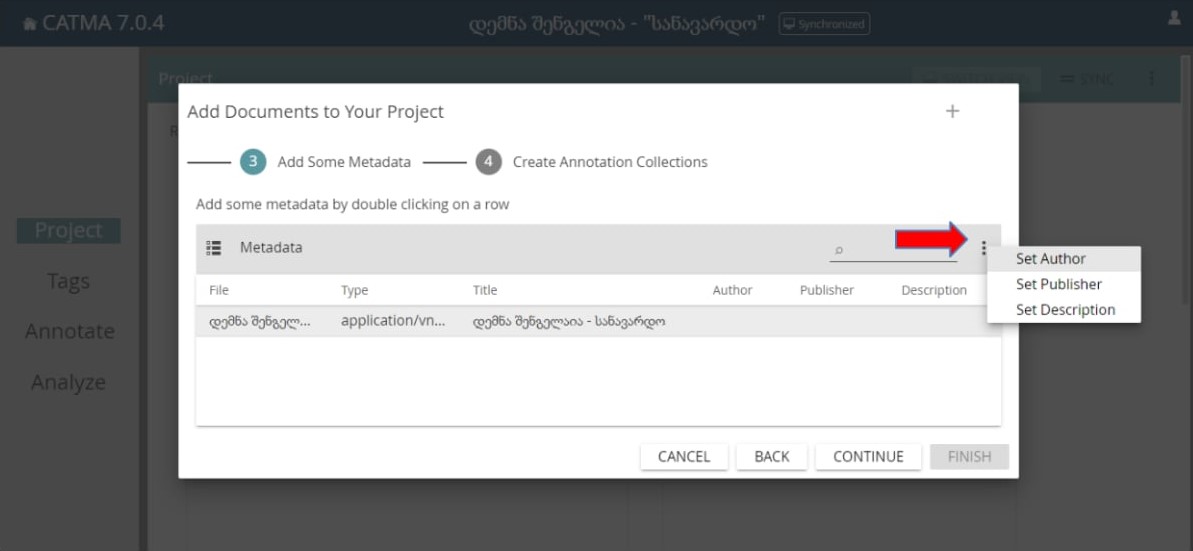
მესამე ეტაპზე შესაძლებელია მეტაინფორმაციის დამატება,
მარჯვნივ არსებული ვერტიკალური სამწერტილის მეშვეობით შეგიძლიათ დაამატოთ ტექსტის ავტორი, გამომცემლობა ან აღწერა:
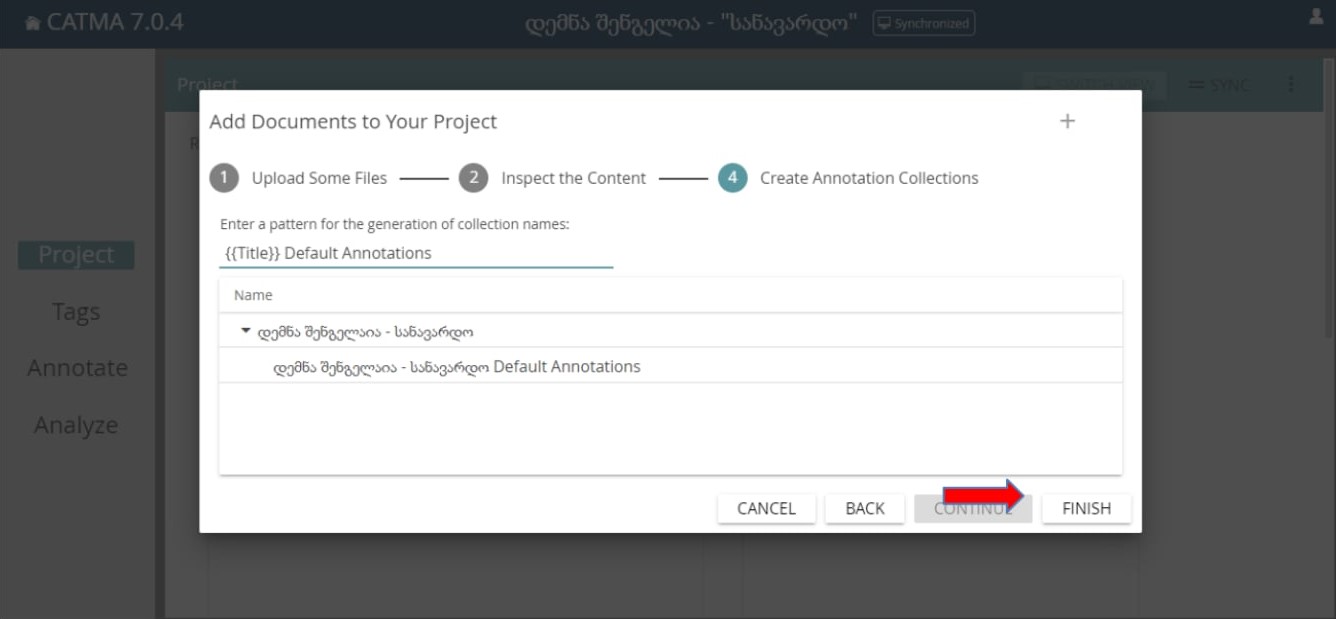
მეოთხე ეტაპზე ვირჩევთ “Finish”-ს, რითაც დასრულდება ტექსტის ატვირთვის ეტაპი:
პროექტის დამატების შემდგომ სამუშაო სივრცის საწყისი გვერდი - Project - ასეთი იქნება:
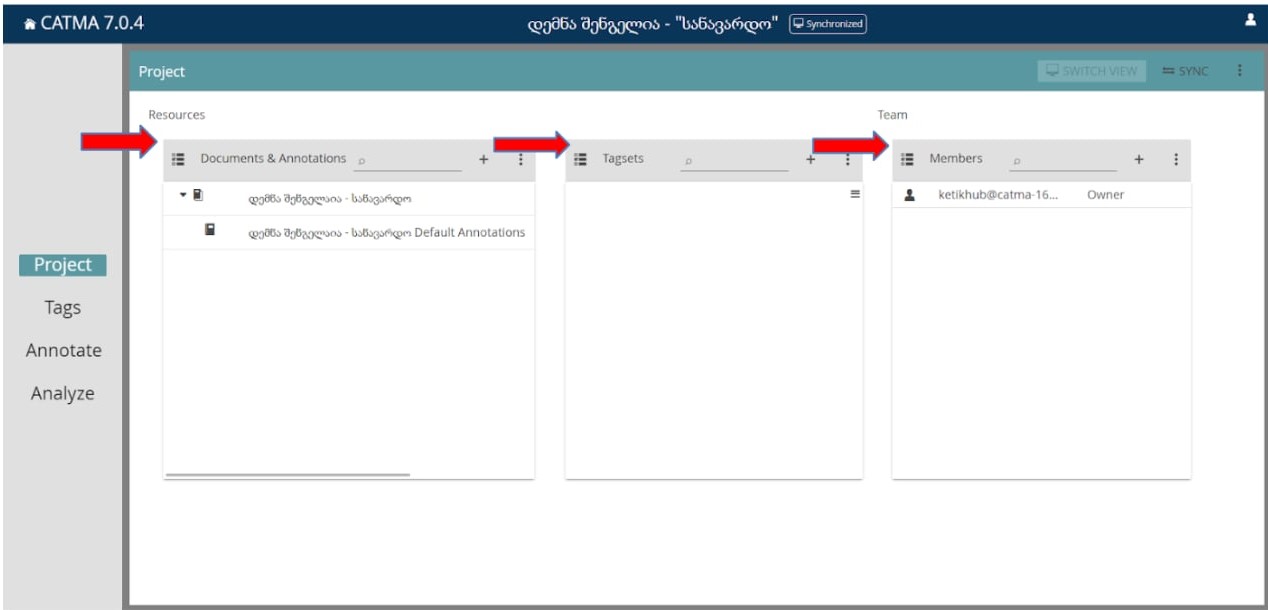
მოცემულ სურათში ჩვენ ვდგავართ პირველ გვერდზე - “Project”, სადაც ასახულია:
- ჩვენ მიერ ატვირთული დოკუმენტი ანოტირებისთვის.
- Tagsat-ები. N13 ფოტოში თეგსეთების ველი ცარიელია, რადგან ჯერ არცერთი თეგსეთი არ არის შექმნილი.
Tagsat - ერთი სახელის ქვეშ აერთიანებს სხვადასხვა თეგს;
როგორც ზემოთ იყო ნახსენები, მენტალური პროცესების რეპრეზენტაცია შეიძლება მოიცავდეს სხვადასხვა თეგს: პირდაპირ ფიქრს, ირიბ ფიქრს …
ასეთ შემთხვევაში “მენტალური პროცესების პრეზენტაცია” იქნება თეგსეთი, ხოლო “პირდაპირი ფიქრი” და “ირიბი ფიქრი” ამ თეგსეთის თეგები.
პროექტისთვის კვლევის მიზნის შესაბამისად, შესაძლოა, შეიქმნას ერთი ან რამდენიმე თეგსეთი შესაბამისი თეგებით.
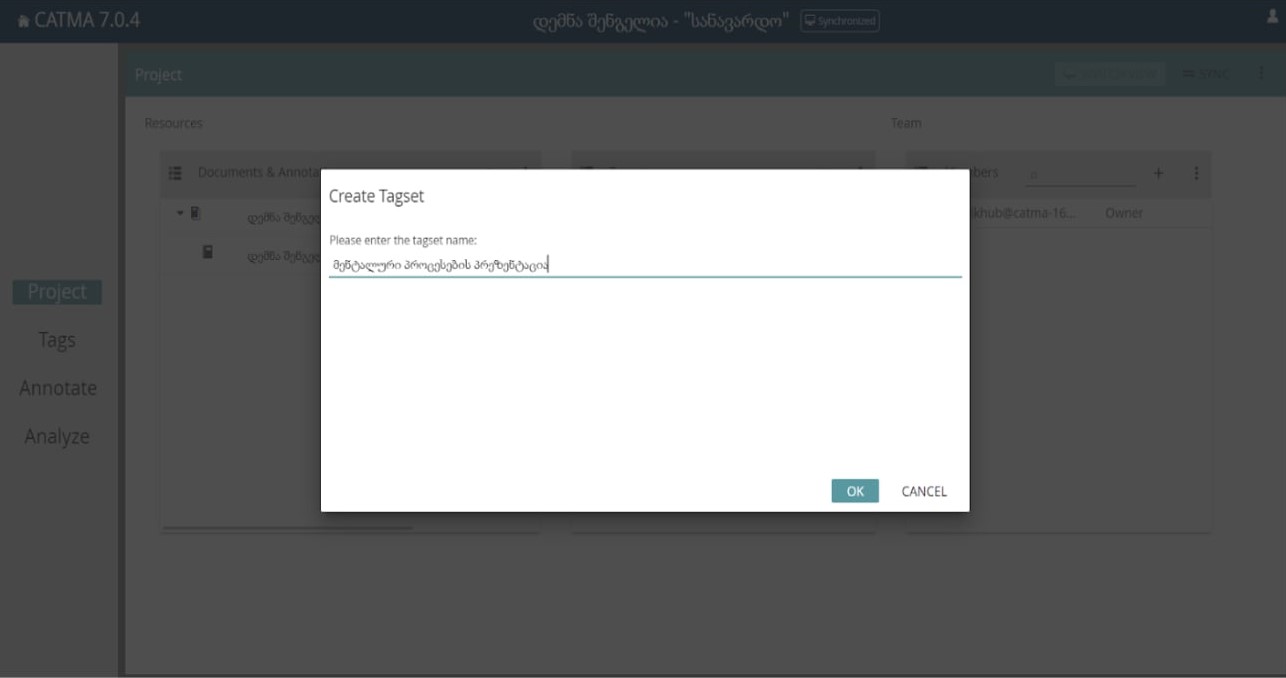
თეგსეთის შექმნა შესაძლებელია თეგსეთის გრაფასთან არსებული + ღილაკის გამოყენებით. Როგორც ნაჩვენებია N14-ე სურათში.
არსებული თეგსეთის შეცვლა ან წაშლა კი ვერტიკალურად განლაგებული სამწერტილის საშუალებით არის შესაძლებელი. - პროექტის წევრები;
ამ შემთხვევაში პროექტს ჰყავს მხოლოდ ერთი წევრი.
წევრის დასამატებლად კვლავ ვიყენებთ + ღილაკს.
ცვლილებების შესატანად ან არსებული მონაწილის წასაშლელად კი კვლავ ვერტიკალურად განლაგებულ სამწერტილს.
უკვე შეგვიძლია ვნახოთ, როგორია მეორე გვერდი - Tags.
აქ დაგვხვდება ჩვენ მიერ შექმნილი თეგსეთები.
ამ შემთხვევაში ასახულია ორი თეგსეთი:
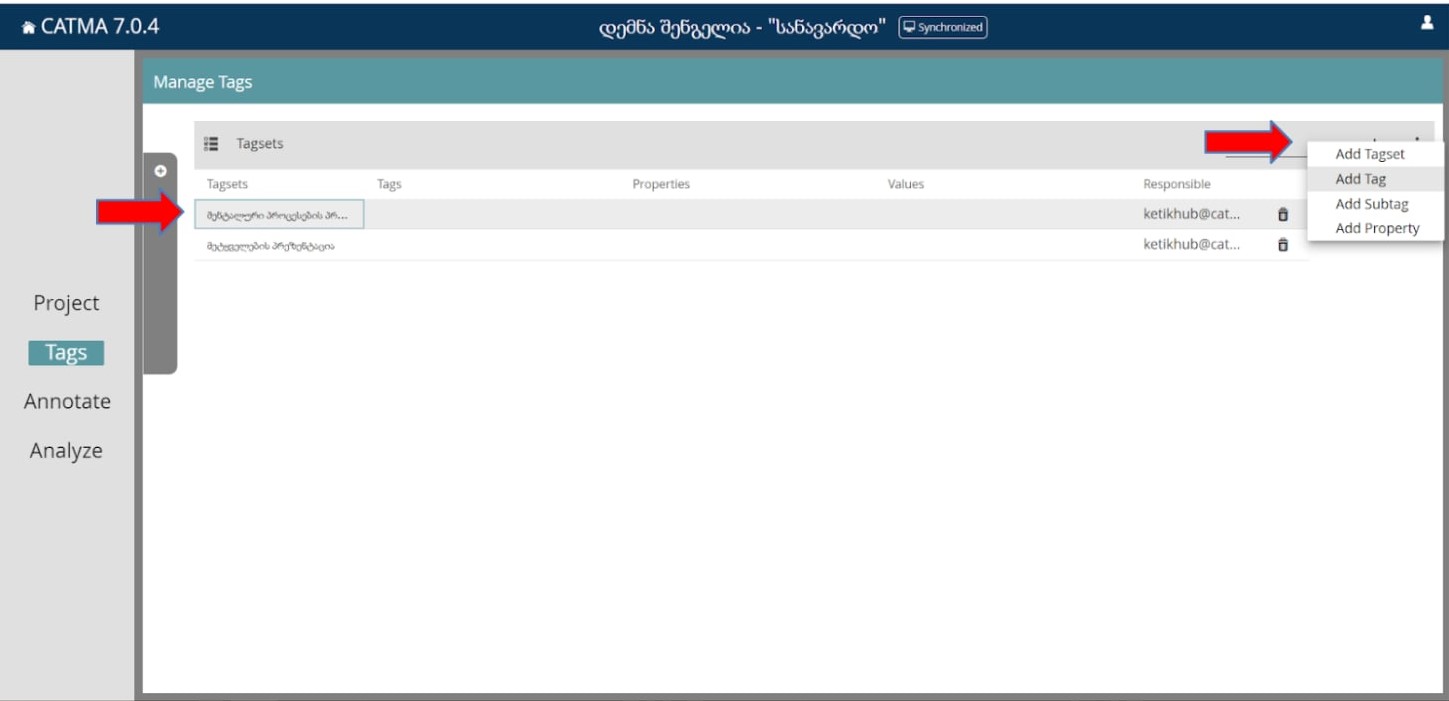
მარჯვნივ ჩანს იმ მკვლევრის ელექტრონული მისამართი, ვინც შექმნა კონკრეტული თეგსეთი.
თეგსეთის წაშლა შესაძლებელია “ყუთის” სიმბოლოს საშუალებით.
იმისთვის, რომ თეგსეთში დავამატოთ თეგები, უნდა ამოვირჩიოთ თეგსეთი მაუსის დაწკაპუნებით და მარჯვენა კუთხეში + ღილაკის დაჭერის შემდეგ, ავარჩიოთ ოფცია “Add Tag”:
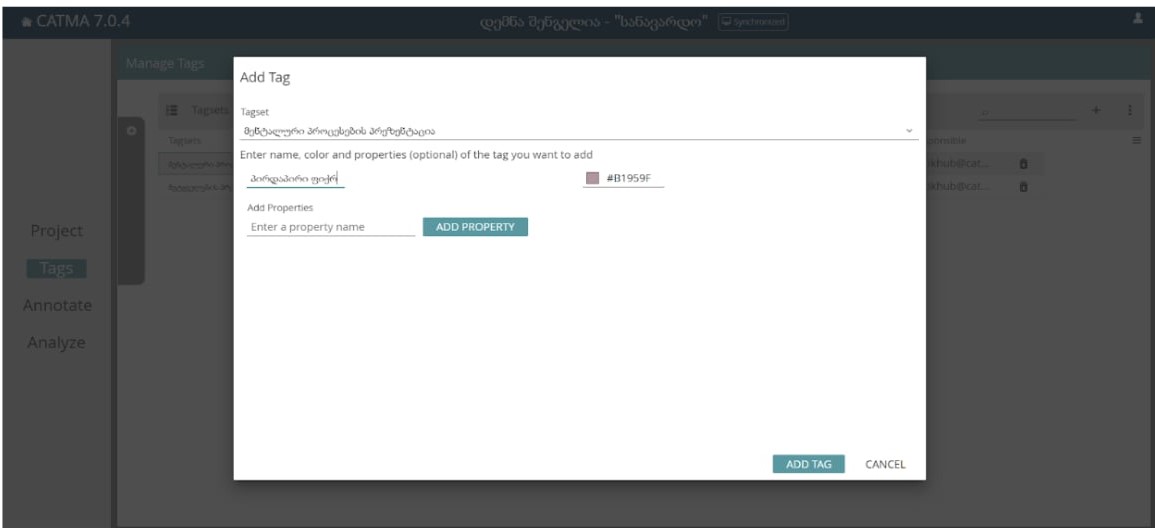
აქ პირველ ველში ასახულია თეგსეთის სახელი, მეორე გრაფაში კი დავწერთ ახალ თეგს, ამ შემთხვევაში “პირდაპირი ფიქრი”, ასევე შეგვიძლია შევარჩიოთ ფერი თეგისთვის.
ბოლოს ინფორმაციის დასამახსოვრებლად და თეგის დასამატებლად ვირჩევთ ოფციას “ADD TAG”.
მას შემდეგ, რაც თითოეულ თეგსეთში დავამატებთ სასურველ თეგებს, Tags მოდული გამოიყურება ასე:
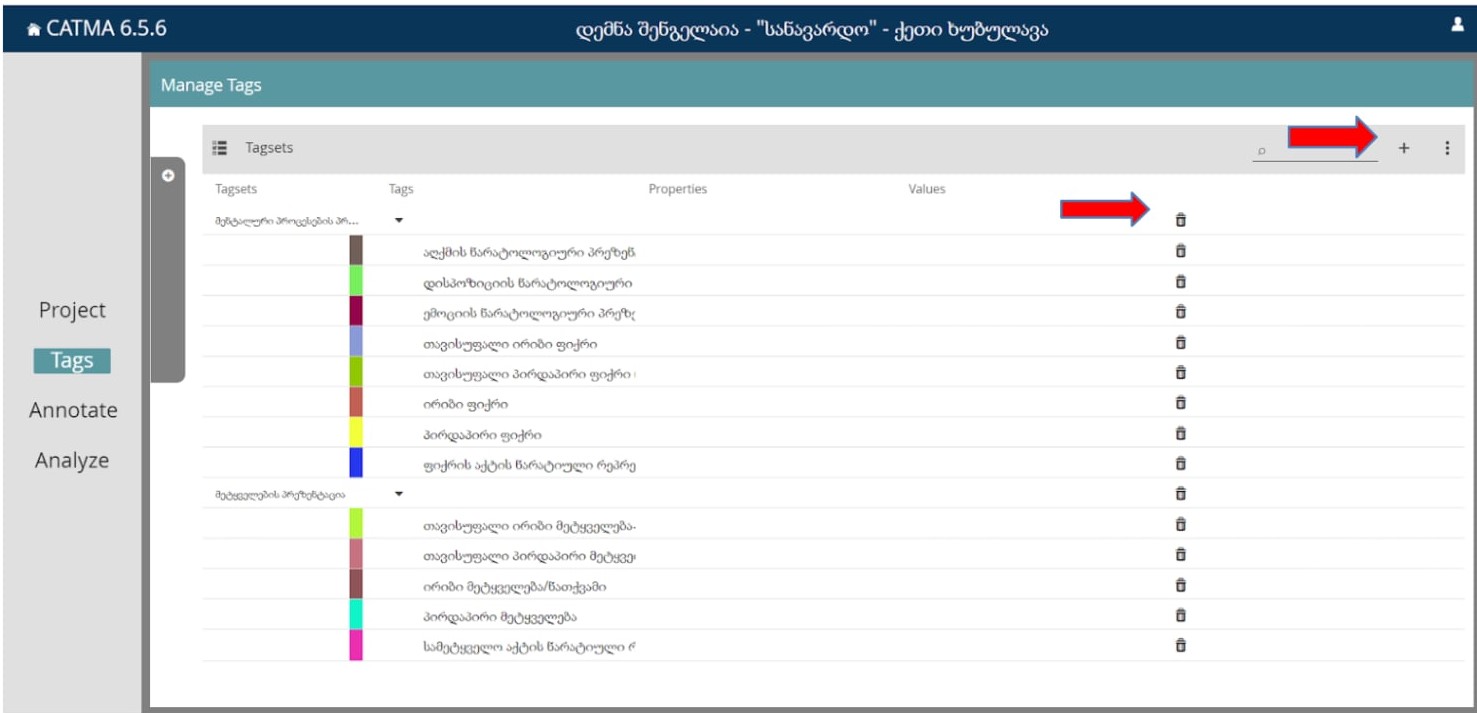
ვერტიკალურად განლაგებული სამწერტილით შესაძლებელია ცვლილებების შეტანა.
მესამე გვერდი, სადაც მკვლევარი მუშაობის პროცესში ყველაზე მეტ დროს ატარებს - Annotate - ასეთია:
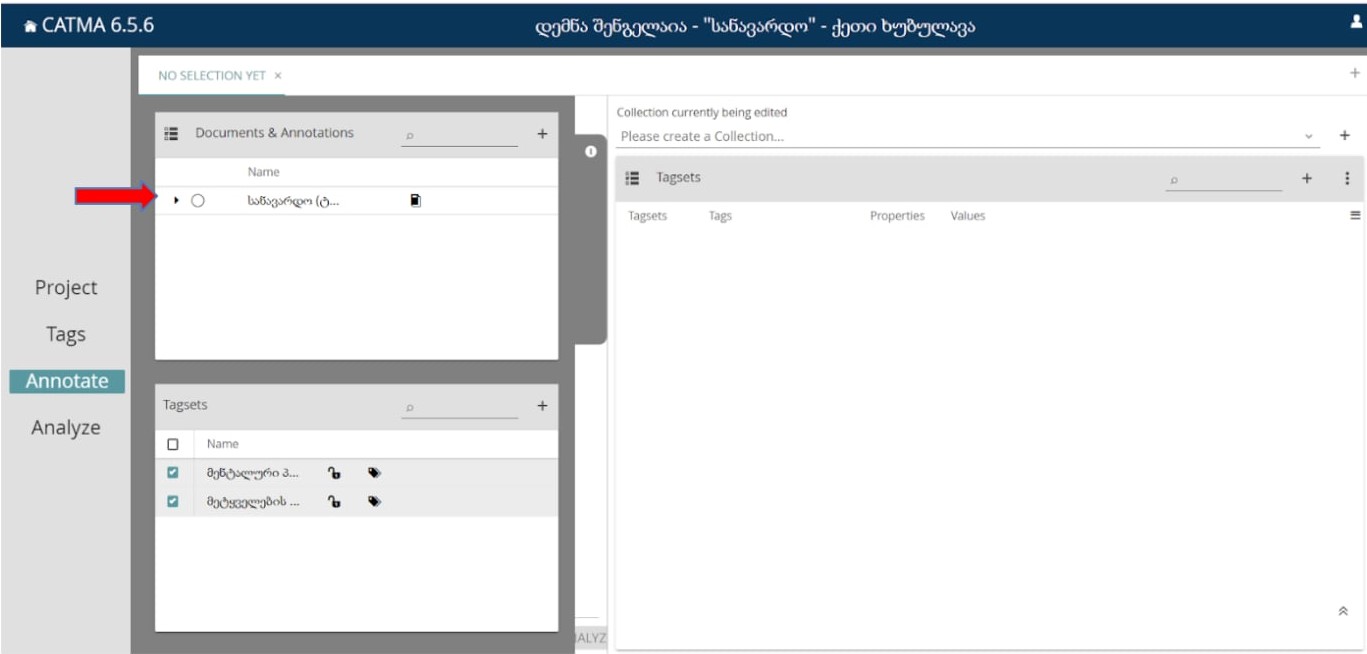
მას შემდეგ, რაც მოვნიშნავთ ტექსტს, გამოჩნდება ასეთი ფანჯარა:
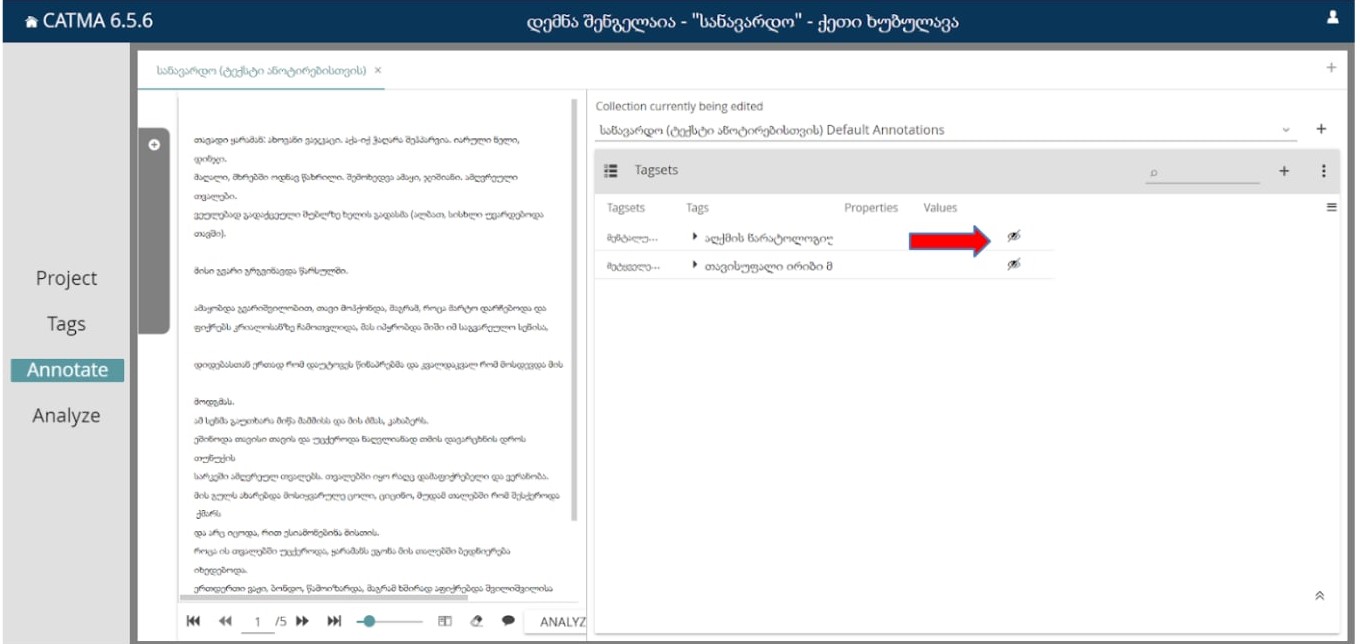
აქ მარცხნივ ჩანს სამუშაო სივრცე - რვეული/წიგნი, მარჯვნივ კი ჩვენ მიერ შექმნილი თეგსეთები.
იმისთვის, რათა თეგებიც გამოჩნდეს, უნდა დავაჭიროთ “თვალის” სიმბოლოს, შემდეგ კი თეგსეთების სახელამდე მოცემულ პატარა სამკუთხედის სიმბოლოს:
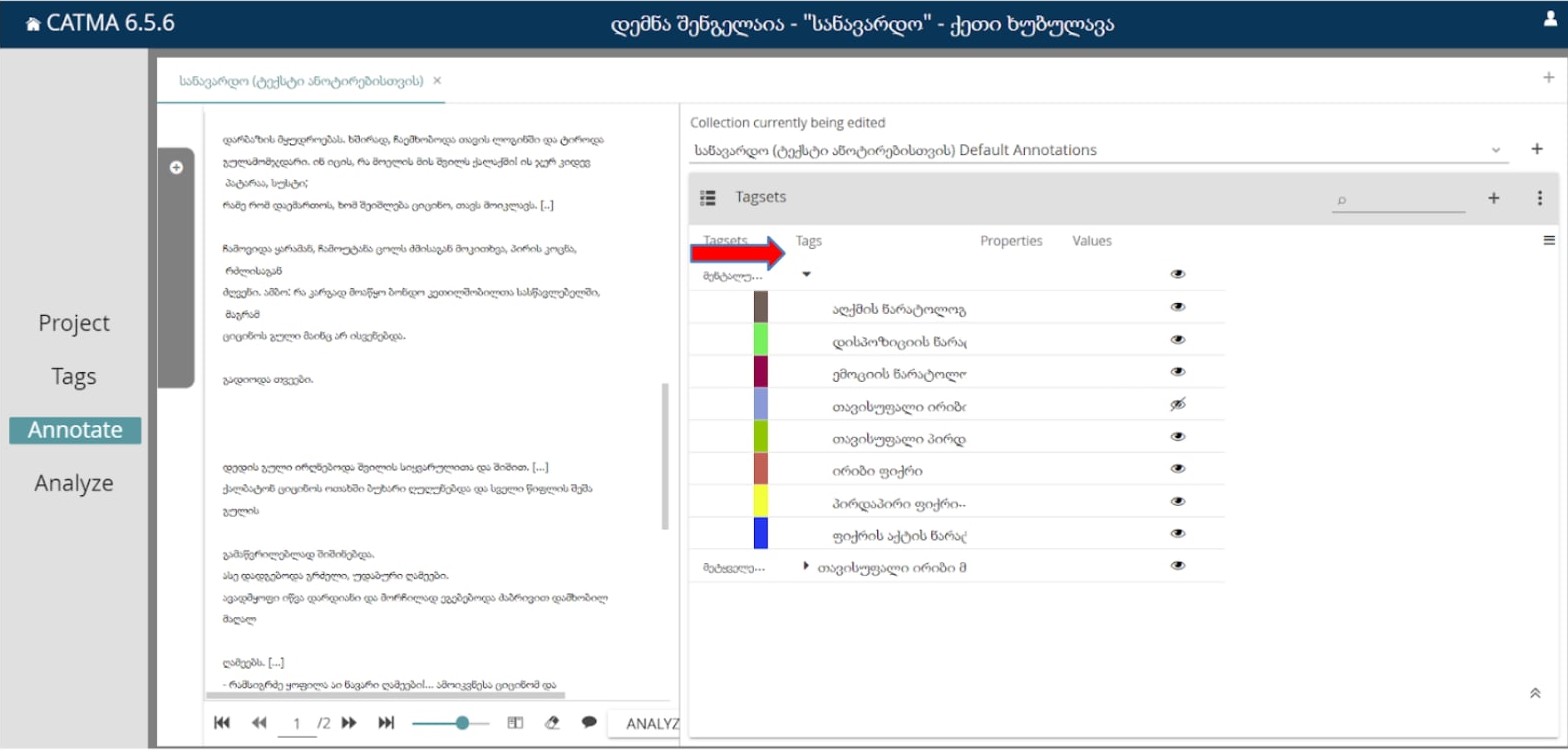
ტექსტის სასურველი ნაწილის კონკრეტული თეგით მოსანიშნად, მაუსის მარცხენა ღილაკით ვნიშნავთ მარკირებისთვის განკუთვნილ სიტყვას/სიტყვებს, ხოლო მაუსის მარჯვენა ნაწილის დაწკაპუნების შემდეგ ჩნდება თეგების ჩამონათვალი, რომლიდანაც ავარჩევთ სასურველ თეგს:
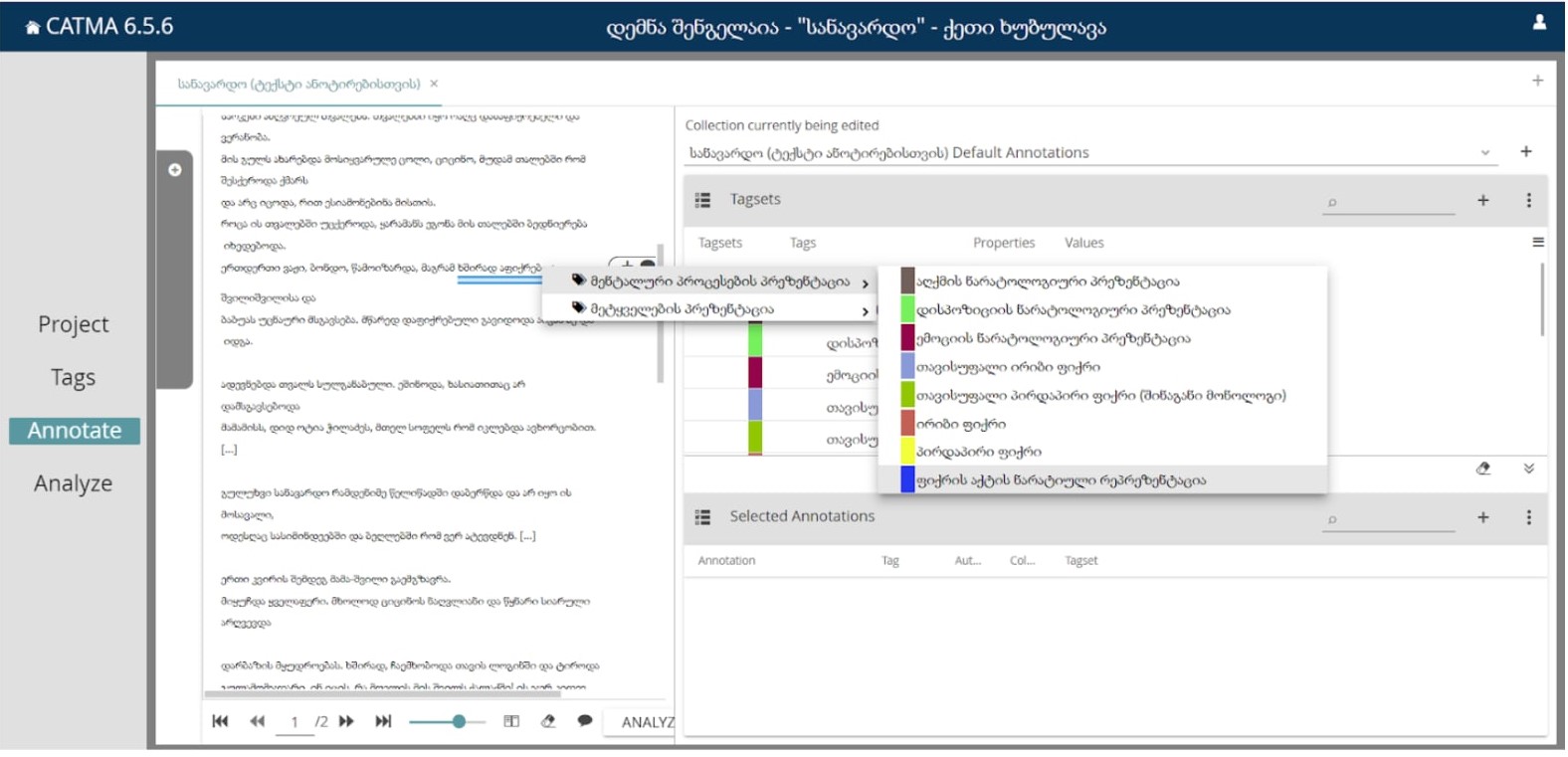
ან შესაძლებელია მოვნიშნოთ ტექსტის სასურველი ნაწილი და შემდეგ მარჯვნივ ჩამოთვლილი თეგებიდან შევარჩიოთ შესაბამისი თეგი.
თუ მარკირების წაშლა დაგვჭირდა, ამას ვაკეთებთ “ყუთის” სიმბოლოს საშუალებით:
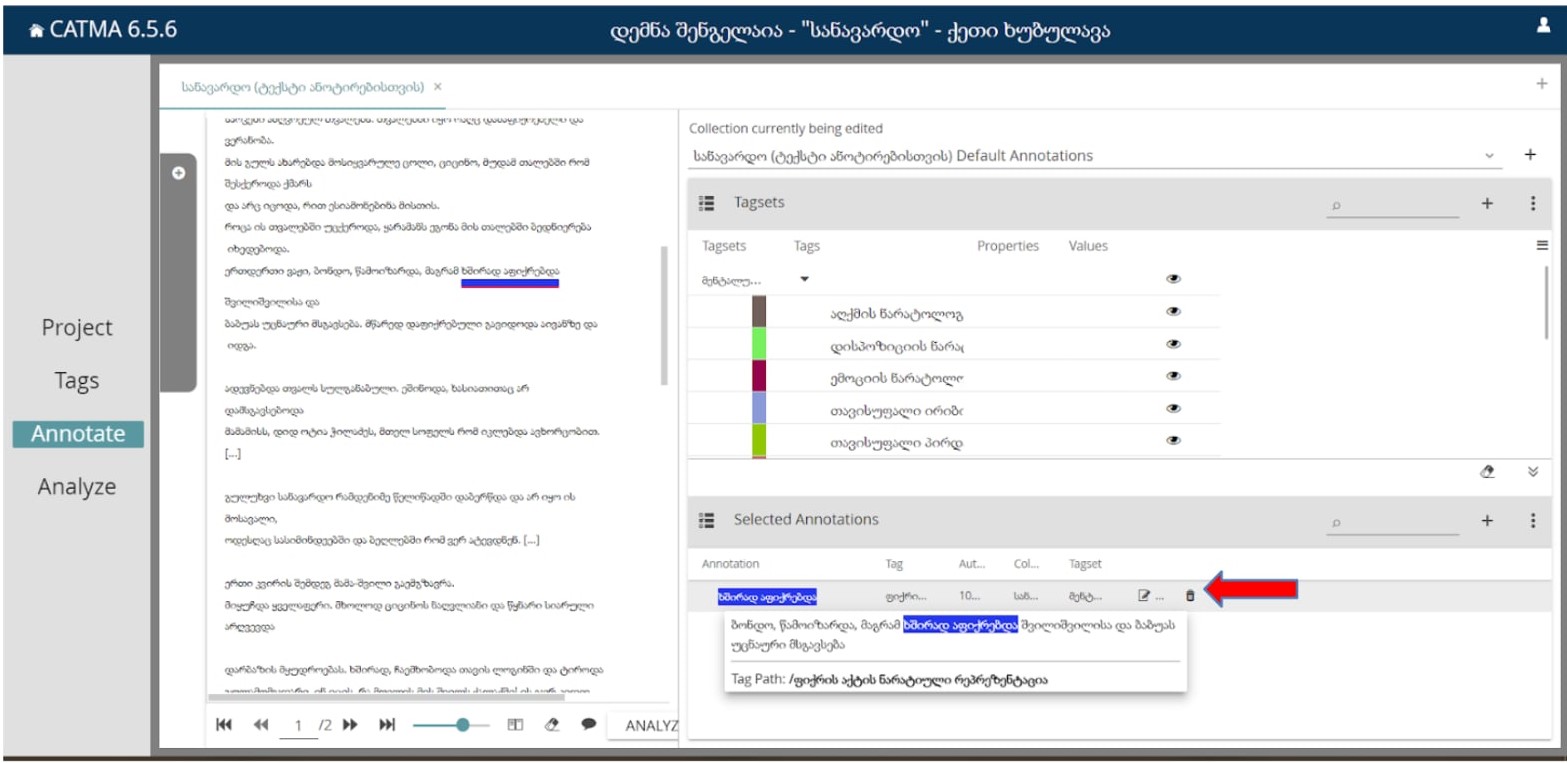
სხვადასხვა თეგით მონიშნული ტექსტი ასე გამოიყურება:
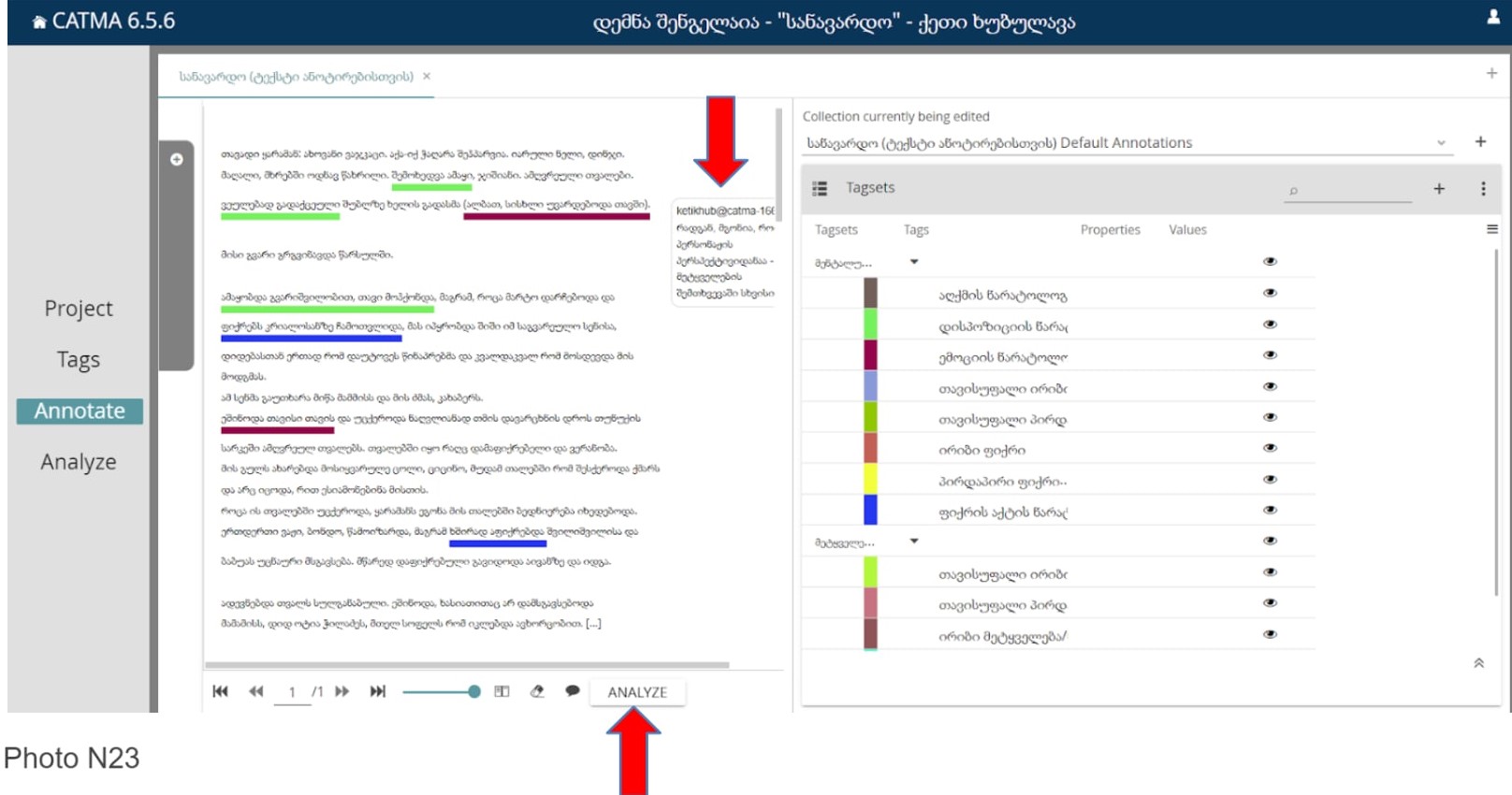
სამუშაო რვეულის მარჯვნივ პატარა ოთხკუთხედში ჩანს კომენტარი - კომენტარი იწყება მკვლევრის მეილის მითითებით, შესაბამისად, როდესაც პროექტში რამდენიმე მკვლევარია ჩართული, მათთვის ნათელი იქნება ეს თუ ის კომენტარი რომელმა მკლევარმა მონიშნა.
კომენტარის შესაქმნელად, მაუსის მარცხენა ღილაკით ვნიშნავთ ტექსტს და ვირჩევთ + ღილაკს.
ბოლო, მეოთხე გვერდი - Analyze - კი ასე გამოიყურება:
ანალიზი შესაძლებელია Annotate მოდულზე ყოფნის დროსაც, რვეულის ქვემოთ Analyze ოფციის მონიშვნით, რომლითაც ავტომატრუად გადავალთ მეოთხე მოდულზე.
ასეთ შემთხვევაში ტექსტი და ანოტაციები ერთობლივად იქნება მზად ანალიზისთვის.
მეორე ვარიანტის არჩევისას, თუ Analyze მოდულზე გადავალთ, უნდა მოვნიშნოთ + ოფცია, რის შემდეგადაც დავინახავთ ასეთ ფანჯარას:
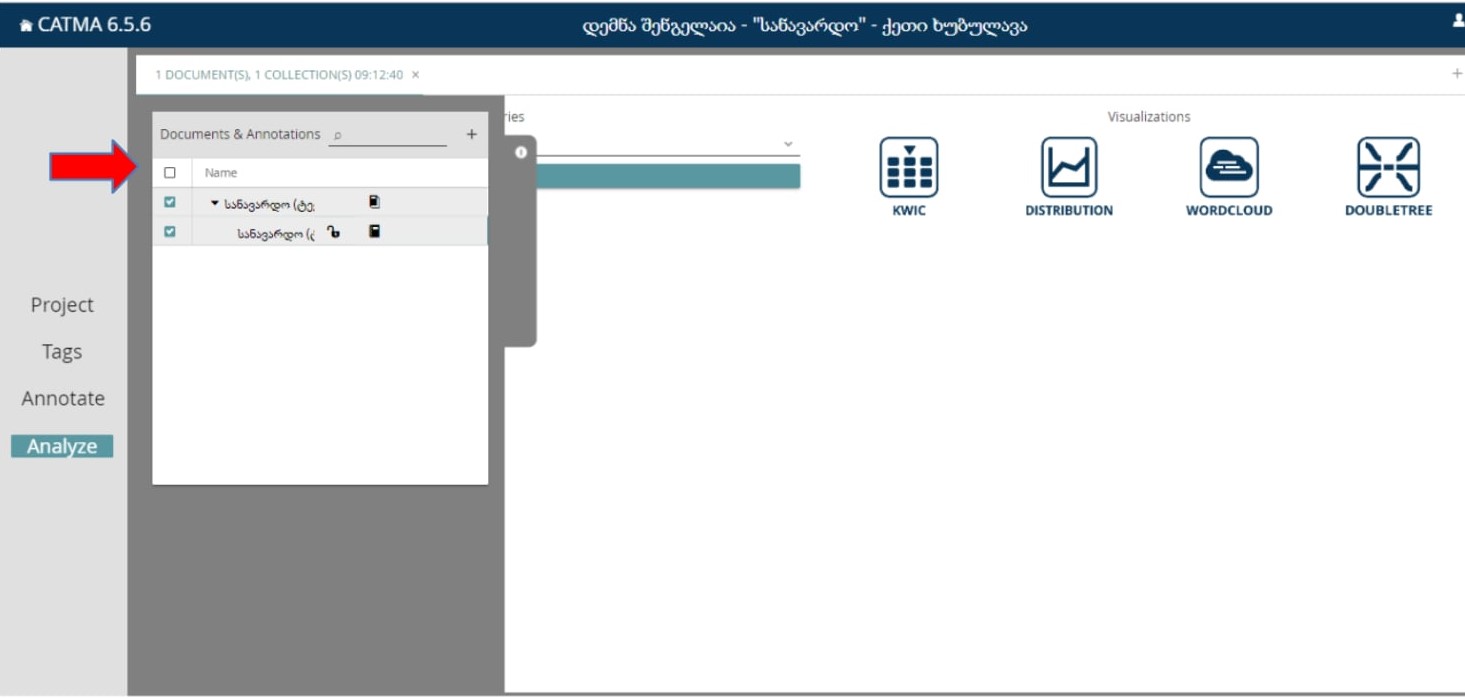
აქ უნდა მოინიშნოს ის, რისი ანალიზიც გვჭირდება.
მონიშვნა იმისთვის არის საჭირო, რადგან კატმას შეუძლია შეასრულოს რაოდენობრივი ანალიზი, როგორც მთლიანი ტექსტისთვის, ასევე ტექსტის მხოლოდ ანოტირებული ნაწილისითვის.
მას შემდეგ, რაც მოვნიშნავთ, რისი ანალიზიც არის საჭირო, ჩვენი ფანჯარა იქნება ისეთი, როგორც არის გამოსახული N24 ფოტოში.
ანალიზის გვერდი იყოფა ორ ნაწილად:
მარცხნივ მოცემულია Queries, ხოლო მარჯვნივ - Visualizations.
Quaries განსაზღვრავს, რა ინფორმაცია არის ამოღებული ტექსტიდან;
Visualizations Quaries-თან არის ინტეგრირებული და მისი მონაცემების ილუსტრირებას ახდენს.
- რა ტიპის მონაცემების დათვლა შეგვიძლია Quaries-ის საშუალებით?
მაგალითად, ჩვენ შეგვიძლია ვნახოთ, თითოეული სიტყვა რამდენჯერ არის ტექსტში გამოყენებული. ამისთვის ვაჭერთ სამკუთხედის სიმბოლოს და ვირჩევთ “Worldlist”-ს.
თუ თეგების ანალიზი გვაინტერესებს, მოვნიშნავთ “Tagsat”-ს.
საილუსტრაციოდ შევარჩიოთ სიტყვათა ანალიზი:
ამ ოპერაციის შესრულების შემდგომ, ჩვენს ტექსტზე დაყრდნობით, გამოჩნდება ფანჯარა, სადაც სიტყვათა სია იქნება წარმოდგენილი:
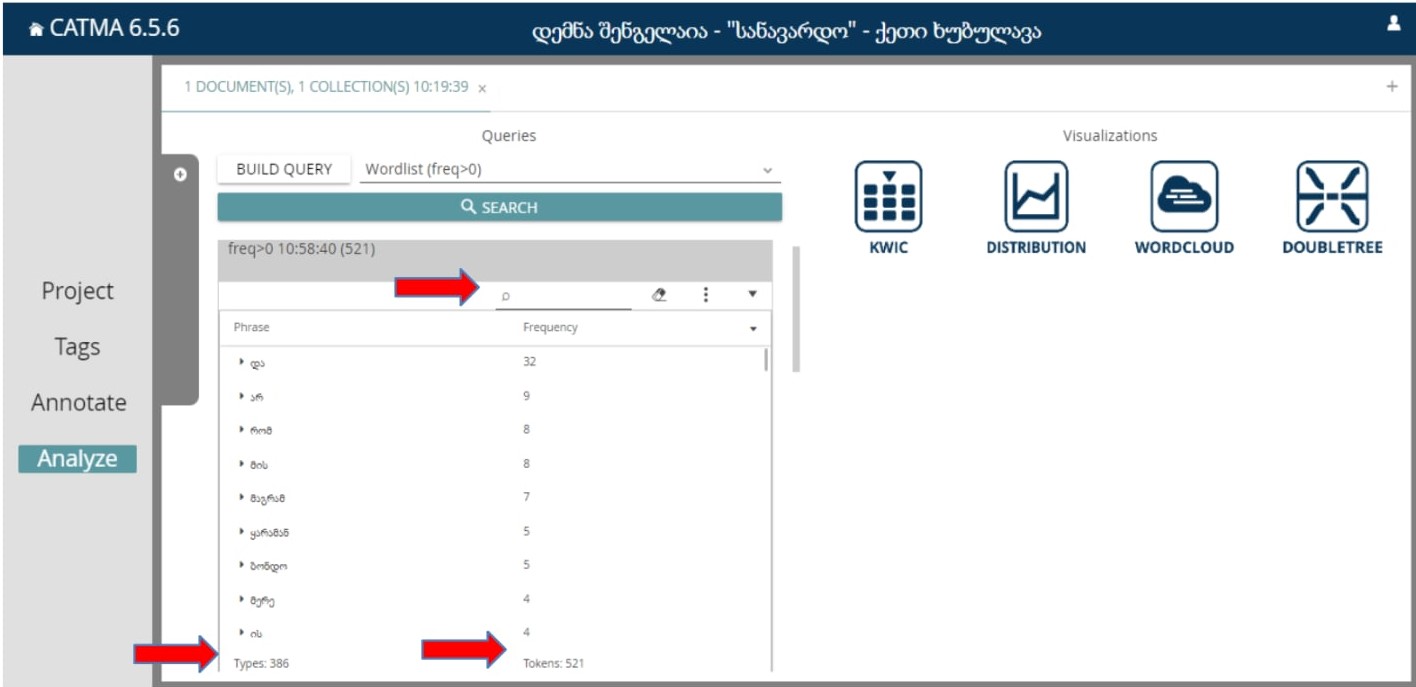
აქ ჩანს, რომ გვაქვს სიტყვათა 386 ტიპი (type) და 521 მონაცემი (token); ტიპი მონაცემზე ნაკლებია, რადგან ტექსტში სხვადასხვა მონაცემი მეორდება.
ყველაზე ხშირად გამოყენებული სიტყვა არის “და” კავშირი (გამოყენებულია 32-ჯერ).
თუ კონკრეტული სიტყვა გვაინტერესებს, შეგვიძლია იგი ავკრიფოთ შესაბამის საძიოებო გრაფაში და გამოჩნდება, იგი რამდენჯერ არის გამოყენებული:
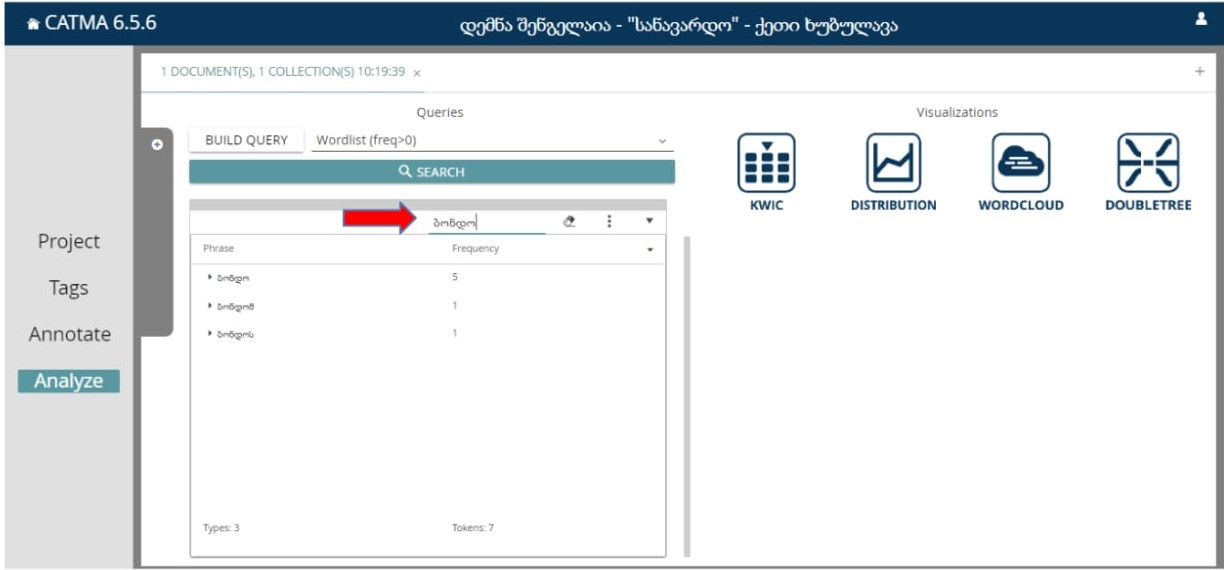
წარმოვადგინოთ ამ რაოდენობრივი ანალიზის ვიზუალიზაცია.
კატმა ვიზუალიზაციის 4 ფორმას გვთავაზობს:
- KWIC
- DISTRIBUTION
- WORDCLOUD
- DOUBLETREE
KWIC-ის საშუალებით შესაძლებელი ხდება, რომ ვნახოთ კონკრეტული სიტყვის კონტექსტი: შესაბამისი ადგილები ტექსტიდან, სადაც ის არის ნახსენები.
ამისთვის ვაჭერთ KWIC გრაფას, დაგვხვდება ასეთი ფანჯარა:
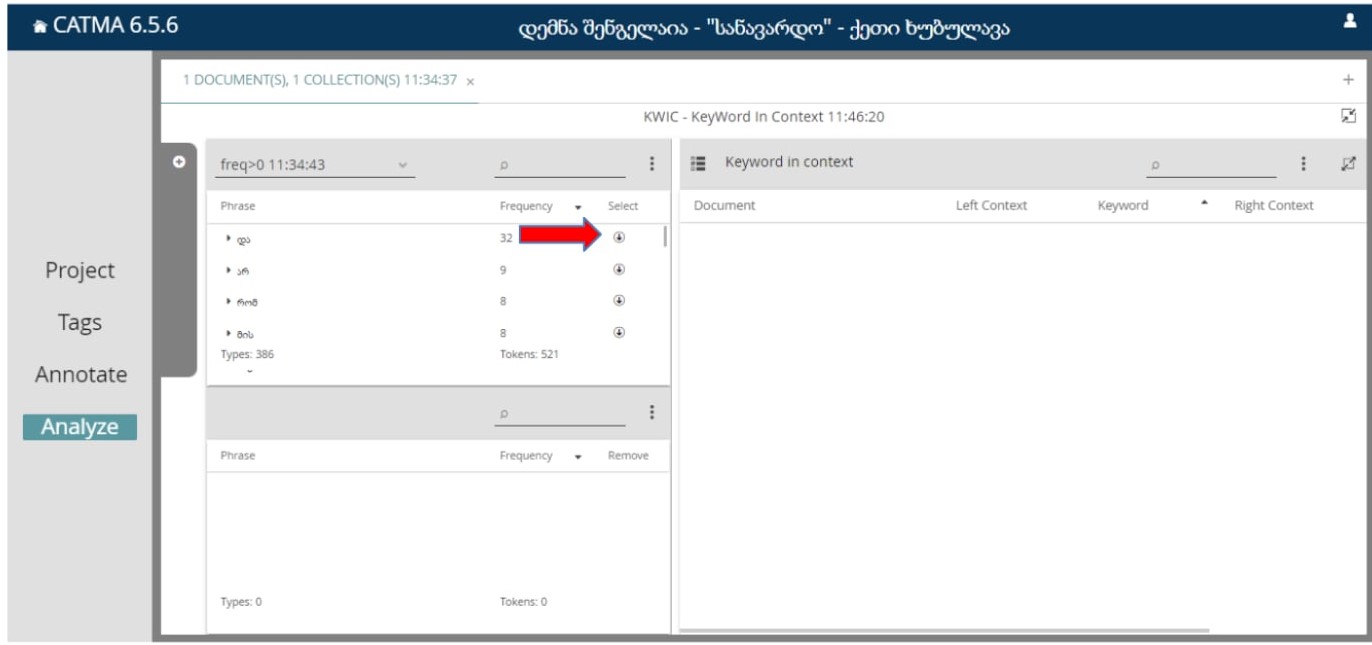
ამის შემდეგ, უნდა ავარჩიოთ სიტყვა, ან სიტყვები, რომლის კონტექსტის ილუსტრირებაც გვჭირდება. ამისთვის უნდა დავაჭიროთ სასურველი სიტყვის გასწვრივ არსებულ ისრის სიმბოლოს.
მაგალითად, ამ შემთხვევაში თუ გვსურს ვნახოთ სიტყვის “არ” კონტექსტი და დავაჭერთ ისრის სიმბოლოს, გამოჩნდება ასეთი ფანჯარა:
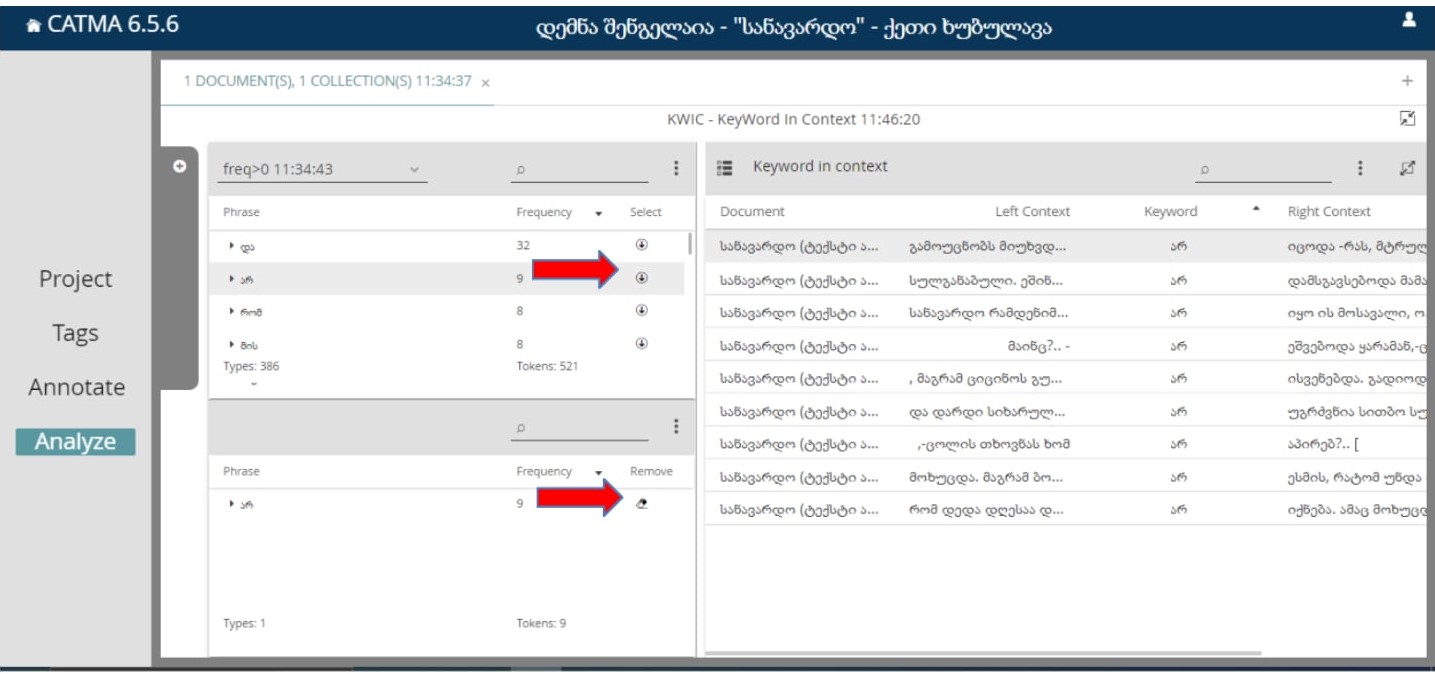
სიტყვა “არ” გამოყენებულია 9-ჯერ შესაბამისად, მარჯვენა მხარეს გამოჩნდა შესაბამისი 9 კონტექსტი.
თუ უშუალოდ ტექსტში გვაინტერესებს კონკრეტული ადგილი, მაგალითად, პირველივე შემთხვევა სადაც ეს სიტყვა არის გამოყენებული, მაუსის მარცხენა ღილაკით ორჯერ დავაწვებით შესაბამის ველს და კატმა გადაგვიყვანს ანოტირების მოდულში:
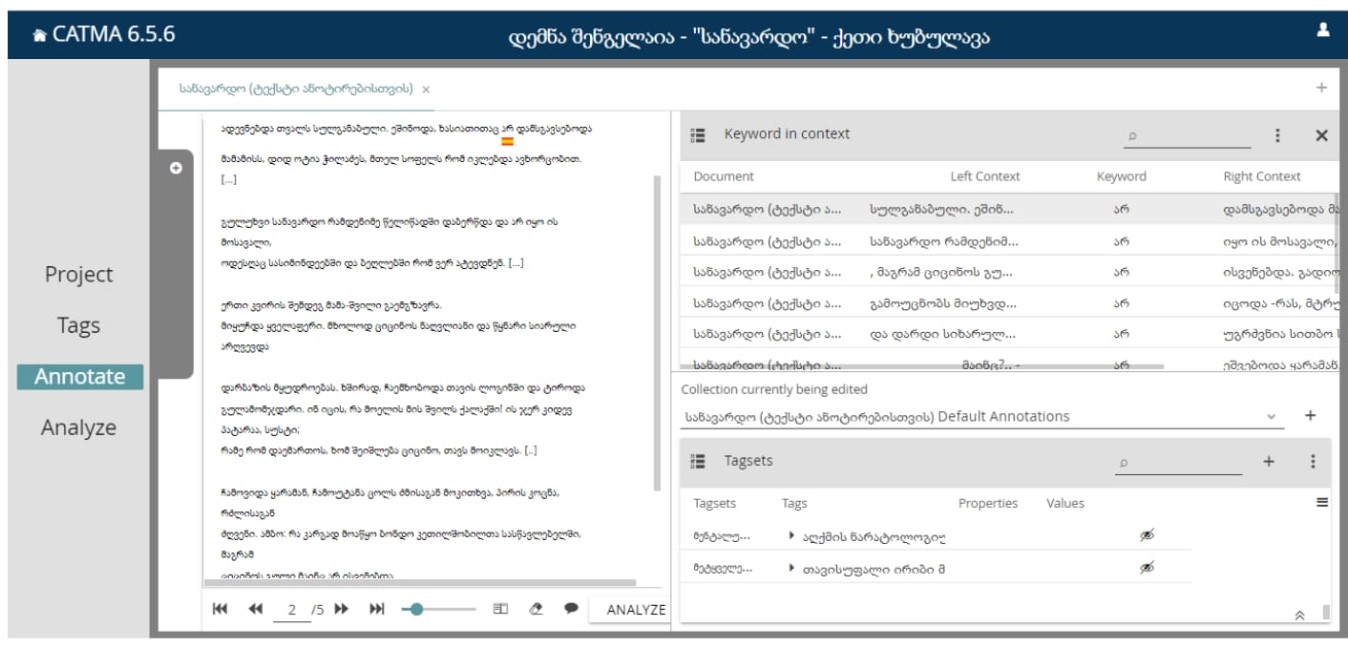
აქ მონიშნულია პირველი შემთხვევა, როდესაც ტექსტში “არ” გვხვდება; ასე არის შესაძლებელი ნებისმიერი ადგილის ნახვა.
დისტრიბუციის საშუალებით შესაძლებელია დიაგრამის საშუალებით ვნახოთ ტექსტის რომელ მონაკვეთში გაოიყენებოდა ესა თუ ის სიტყვა.
დისტრიბუციის არჩევისას დაგვხვდება ასეთი ფანჯარა:
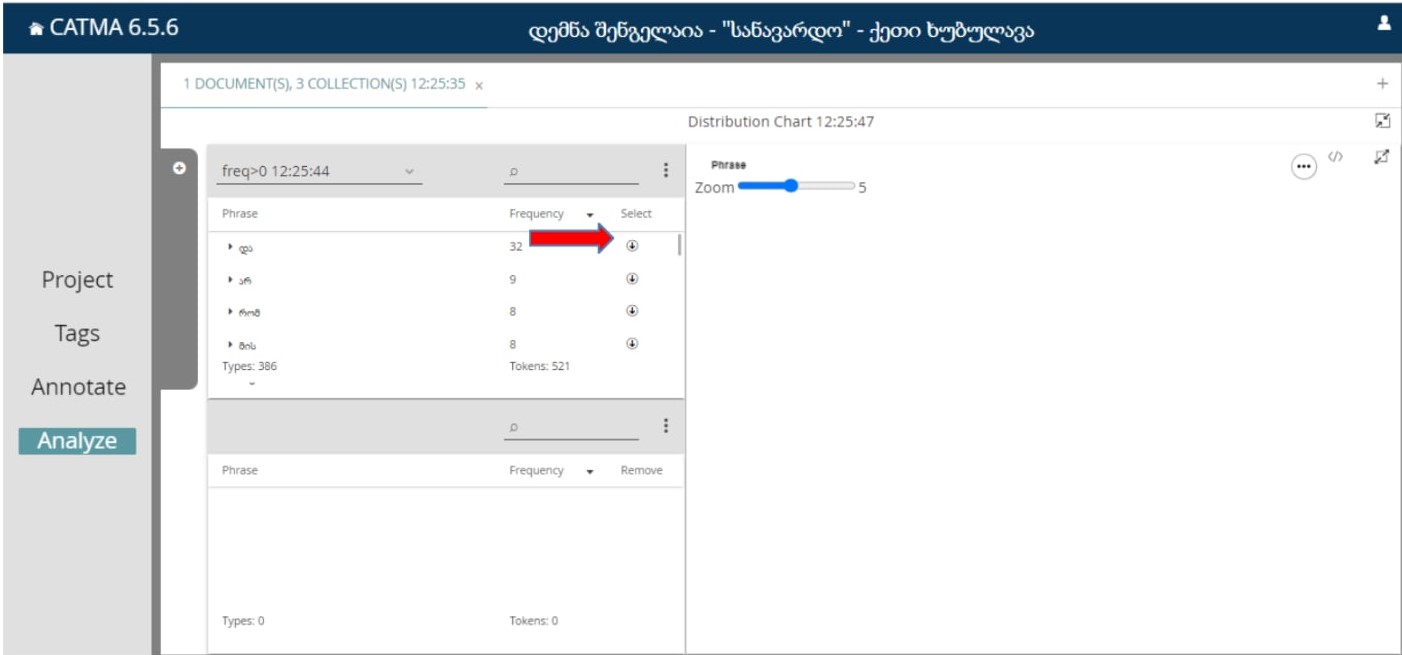
აქაც ისრის საშუალებით უნდა ჩამოვტვირთოთ ის სიტყვები, რომლის ილუსტრირებაც გვინდა.
ვთქვათ, ავირჩიოთ პირველი ორი სიტყვა, მათი დისტრიბუცია იქნება ასეთი:
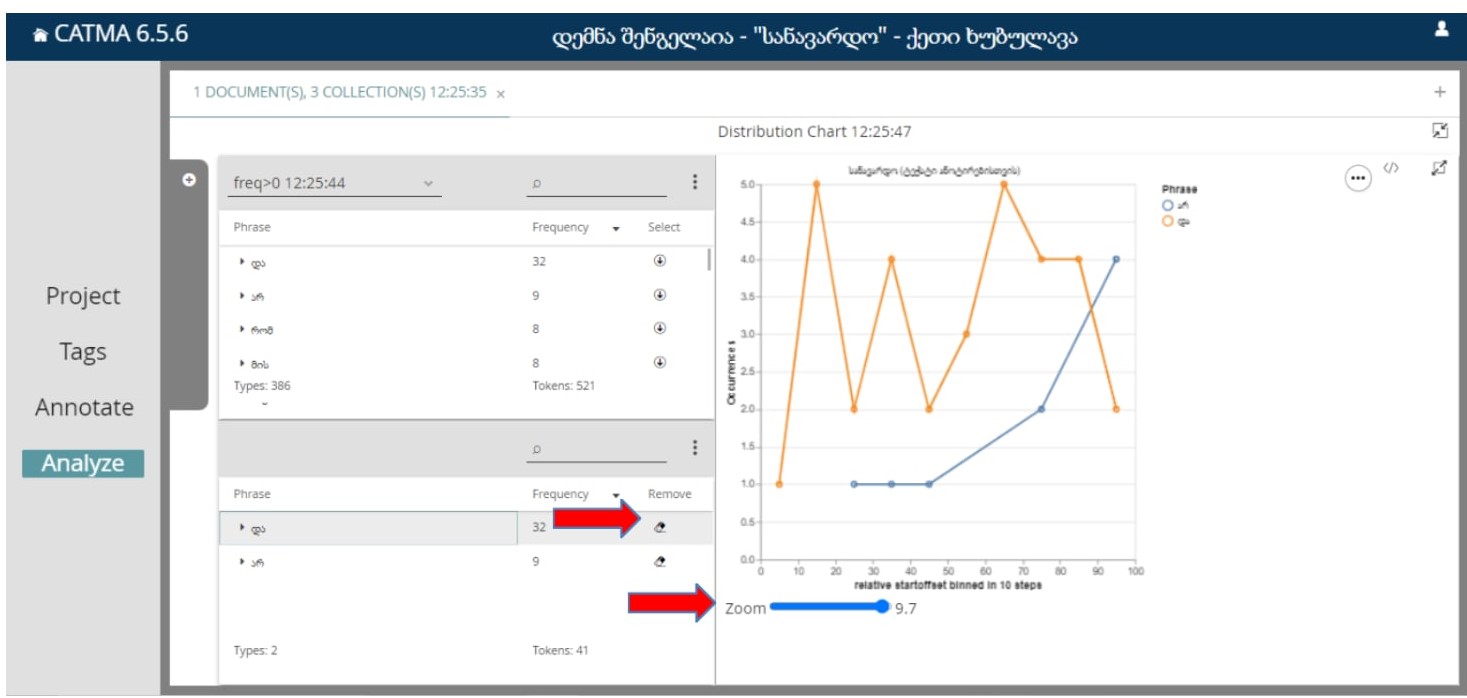
დიაგრამაზე წარმოდგენილია ორი სიტყვის ანალიზი:
სიტყვა “და” მონიშნულია ნარინჯისფრად, ხოლო “არ” - ლურჯად.
დიაგრამის ჰორიზონტალური ხაზი აჩვენებს ტექსტის რა ნაწილში არის წარმოდგენილი კონკრეტული სიტყვა, ვერტიკალური ხაზი კი - რა სიხშირით.
ZOOM-ის საშუალებით შესაძლებელია დიაგრამის ზომის ცვლილება.
სიტყვის წასაშლელად მარცხენა ქვემოთ არსებულ ნაწილში სიტყვის შესაბამისი ველის გასწრვრივ არსებულ “საშლელის” სიმბოლოს ვირჩევთ.
განვიხილოთ სიტყვა “დას” დისტრიბუცია:
ყველაზე მაღალი ამპლიტუდა ჩანს ტექსტის ორ ნაწილში - 10-20 და 60-70 მონაკვეთებში, ე.ი. აქ ამ სიტყვის გამოყენების სიხშირე იყო ყველაზე მაღალი.
დისტრიბუციისთვის შესაძლოა მოინიშნოს ერთი ან რამდენიმე სიტყვა, შესაძლებელია დიაგრამის გადმოწერაც:
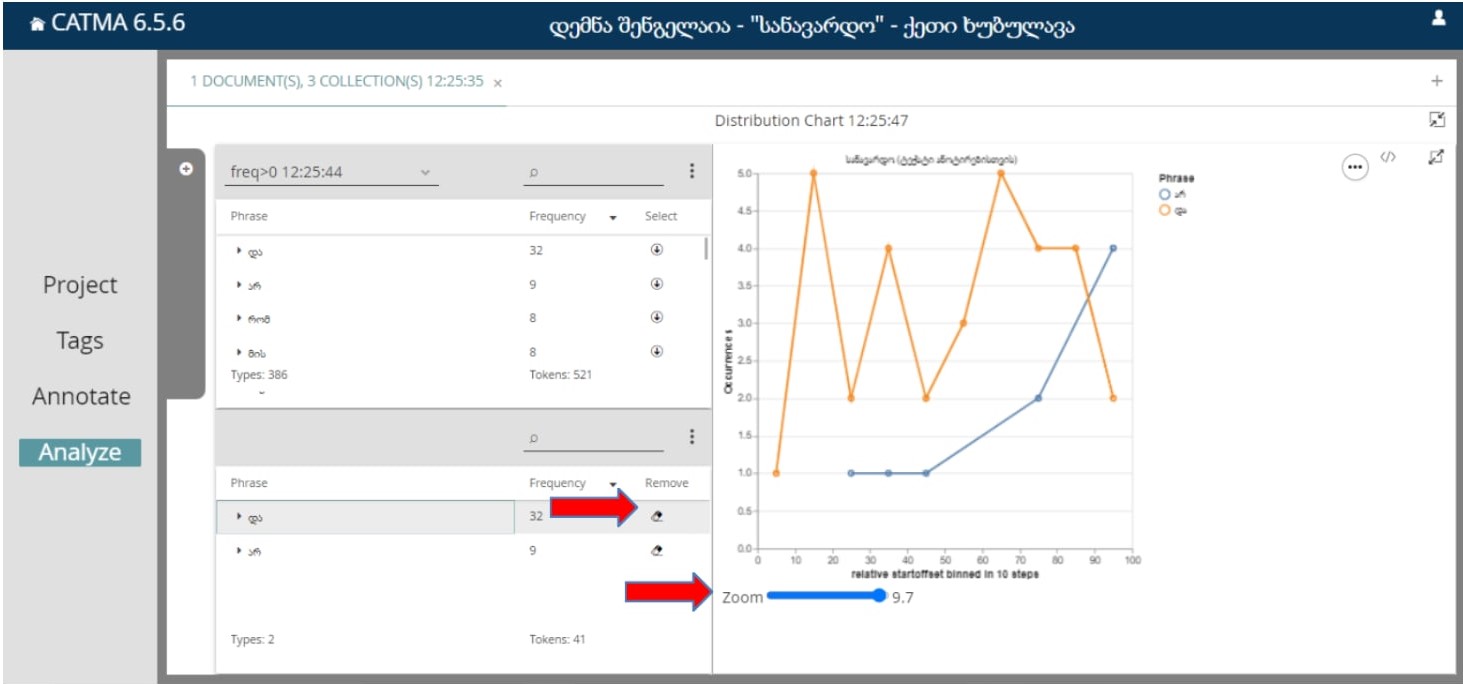
არსებულ დიაგრამაზე გამოსახულია 6 სიტყვის ანალიზი, ჩანს სხვადასხვა სიტყვის კოლერაციის/თანაკვეთის შემთხვევები.
დიაგრამის გადმოსაწერად ვაჭერთ სამწერილს და ვირჩევთ სასურველ ფორმატს გადმოწერისთვის.
WordCloud-ის საშულებით ჩანს “სიტყვათა ღრუბელში” ესა თუ ის სიტყვა რამდენად ხშირად არის წარმოდგენილი:
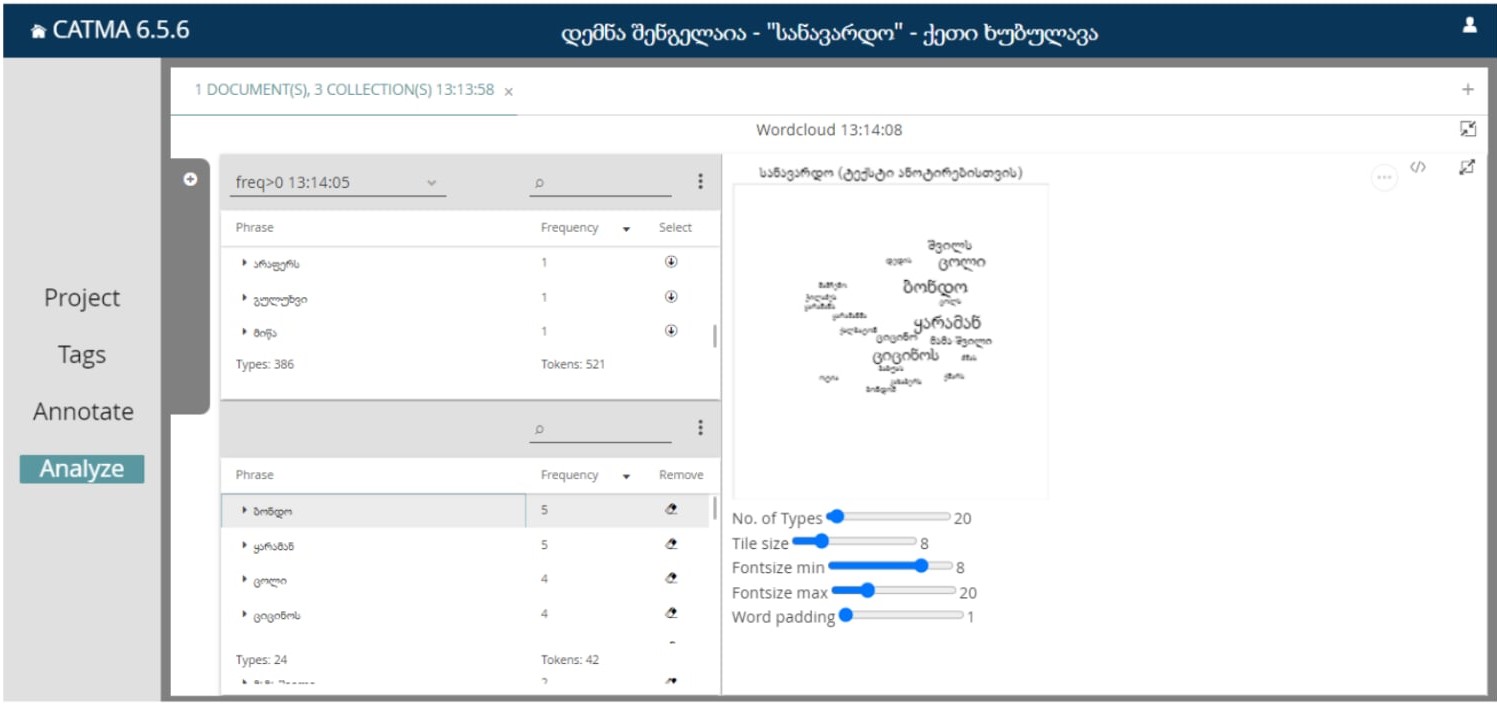
ილუსტრაციისთვის ჩვენი ტექსტიდან ავარჩიეთ პერსონაჟების სახელები, რათა გვენახა რომელი მათგანი არის ყველაზე ხშირად გამოყენებული.
თუ გვსურს ვნახოთ კონკრეტული სიტყვა ტექსტის რომელ ნაწილში არის გამოყენებული, მაშინ მაუსის მარცხენა ღილაკით ვაწვებით შესაბამის სიტყვას და ჩნდება ასეთი ფანჯარა:
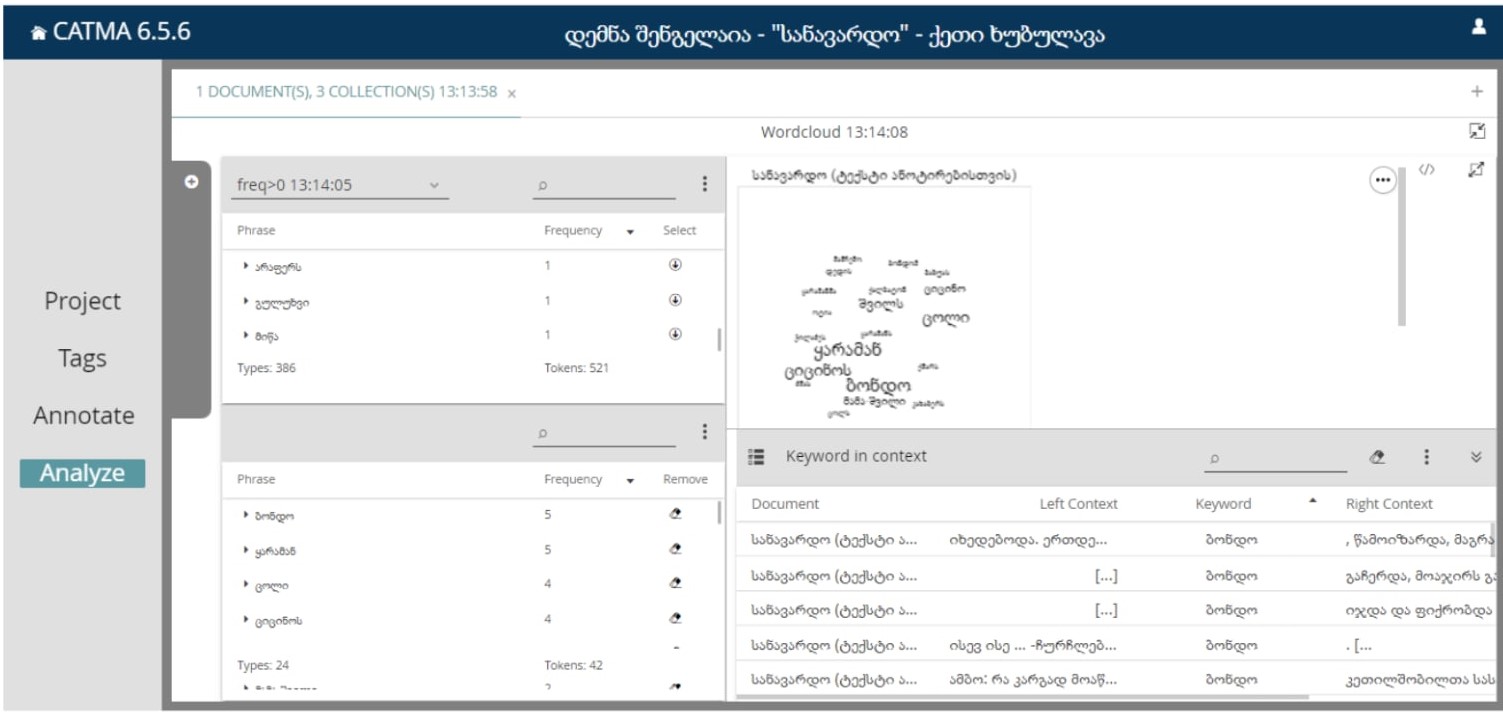
აქ ასახულია ადგილები, სადაც “ბონდო” არის გამოყენებული.
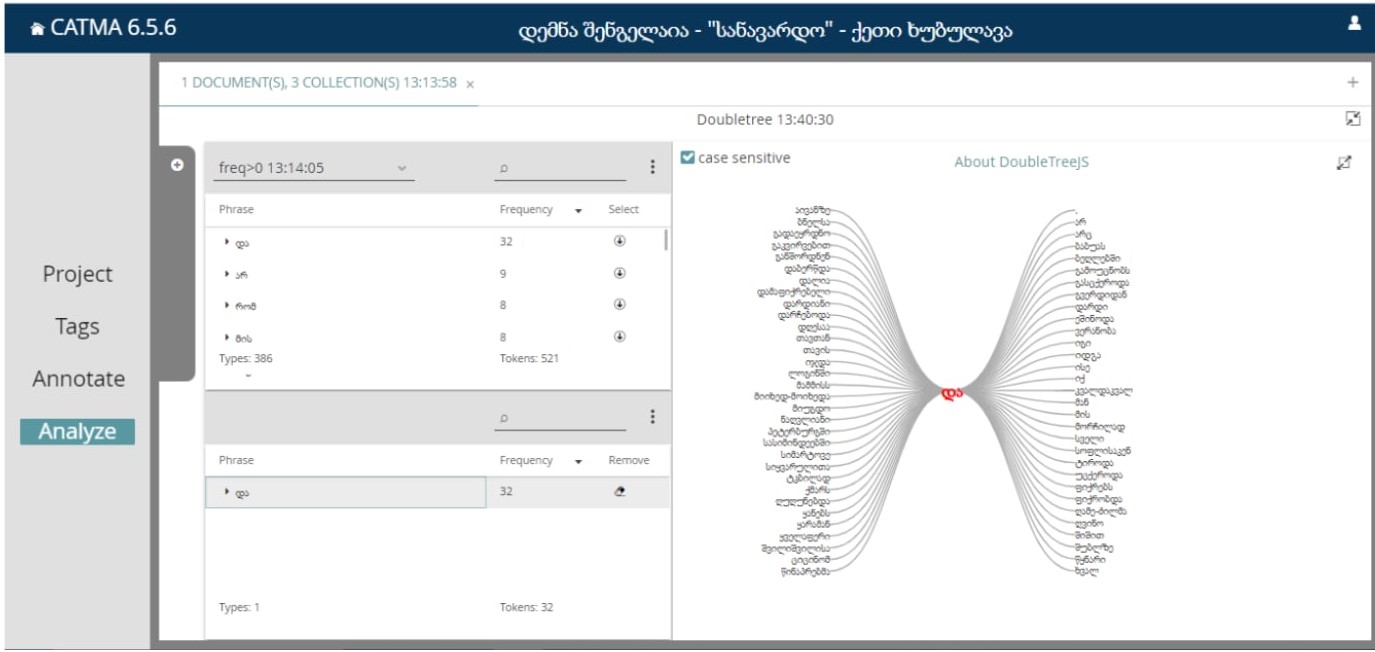
DOUBLETREE-ის საშუალებითაც, ვნიშნავთ სასურველ სიტყვას და ილუსტრაციაში ჩნდება შერჩეული სიტყვა კონტექსტით:
CATMA საშუალებას გვაძლევს, თავად შექმნათ ბრძანება რაოდენობრივი ანალიზის ოპერაციის შესასრულებლად, ამისთვის ვიყენებთ Build The Query გრაფას:
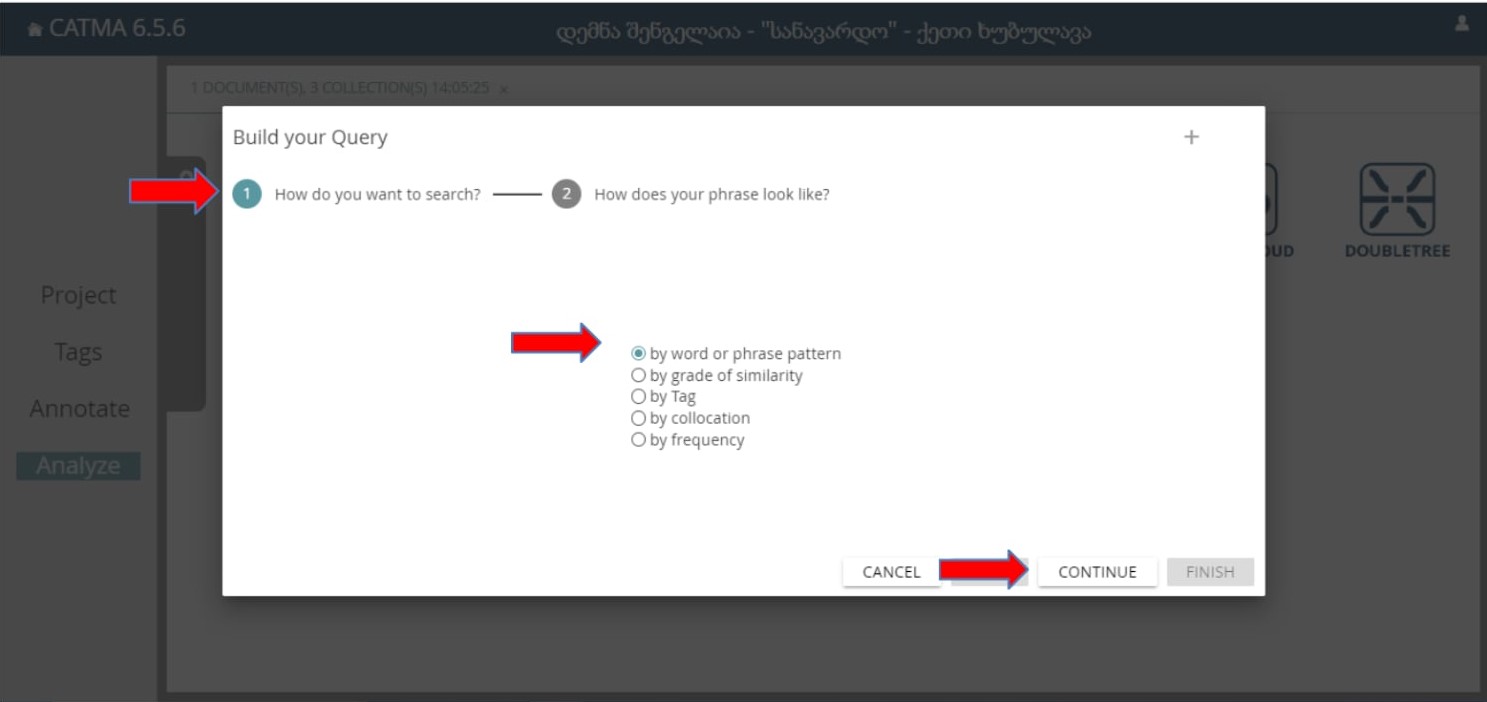
აქ უნდა მოინიშნოს, რისი ანალიზი გვინდა, მაგალითად მოვნიშნოთ პირველი ვარიანტი და დავაჭიროთ CONTINUE-ს.
დავინახავთ ასეთ ფანჯარას:
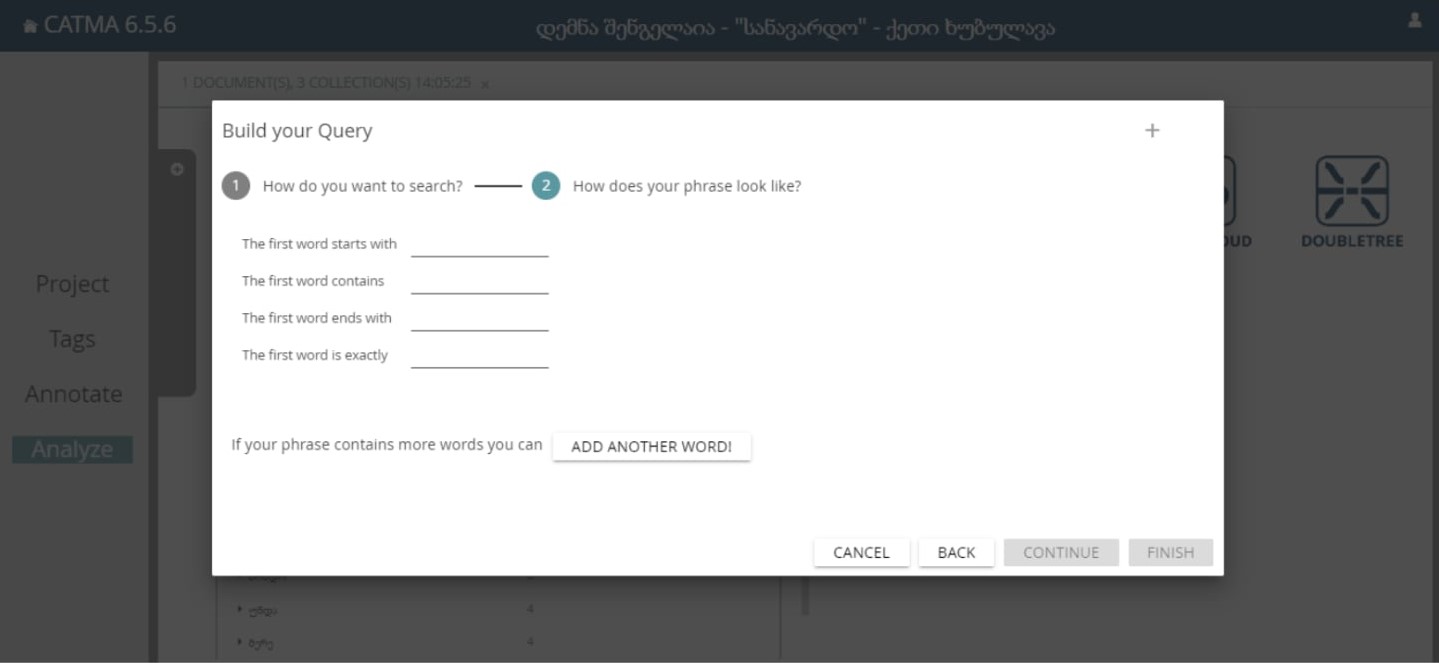
აქ მოვნიშნავთ რა ტიპის სიტყვების მოძიება გვურს.
მაგალითად, გვინდა მოვიძიოთ სიტყვები, რომელიც იწყება ბ ასოზე:
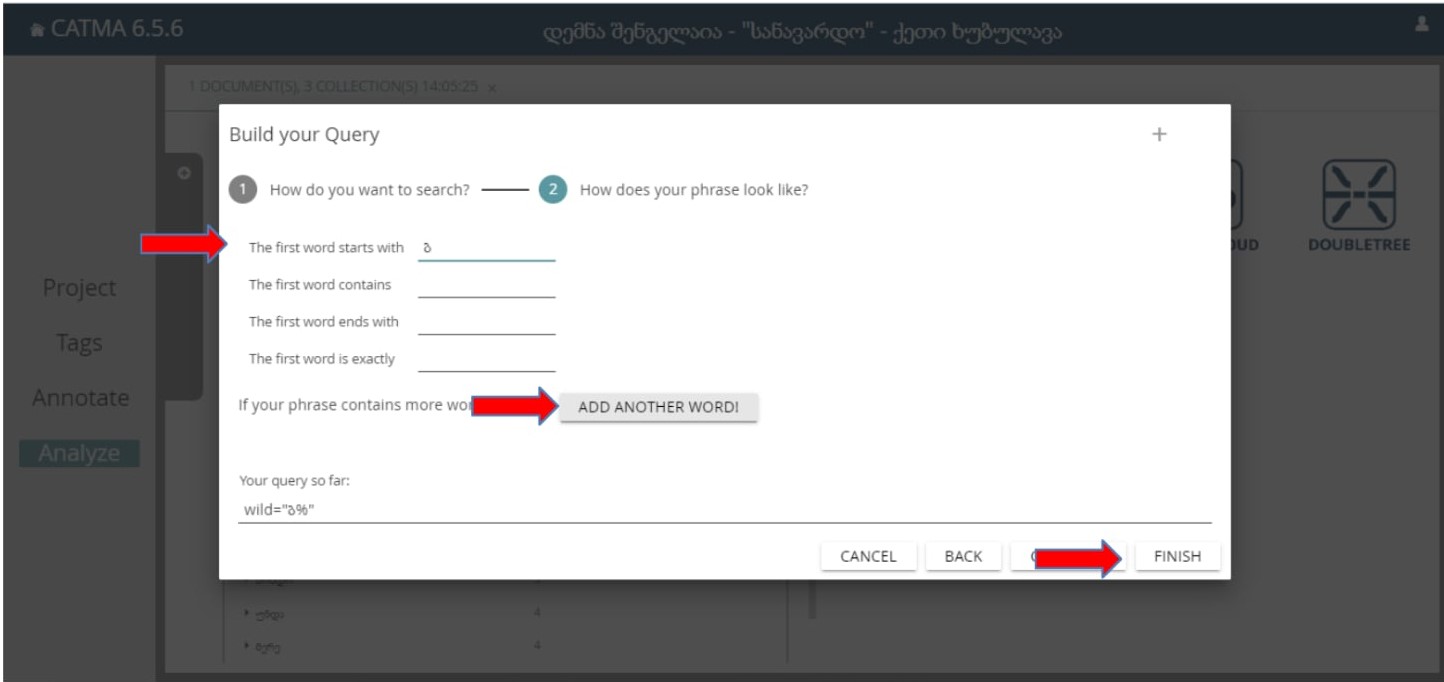
თუ სხვაგვარი სიტყევბის დამატებაც გვსურს ვირჩევთ გრაფას: ADD ANOTHER WORD
ბრძანების დასასრულებლად ვირჩევთ ოფციას “FINISH”.
ამის შემდეგ გვაჩვენებს მონაცემებს, რომლებიც იწყებს ბ ასოზე:
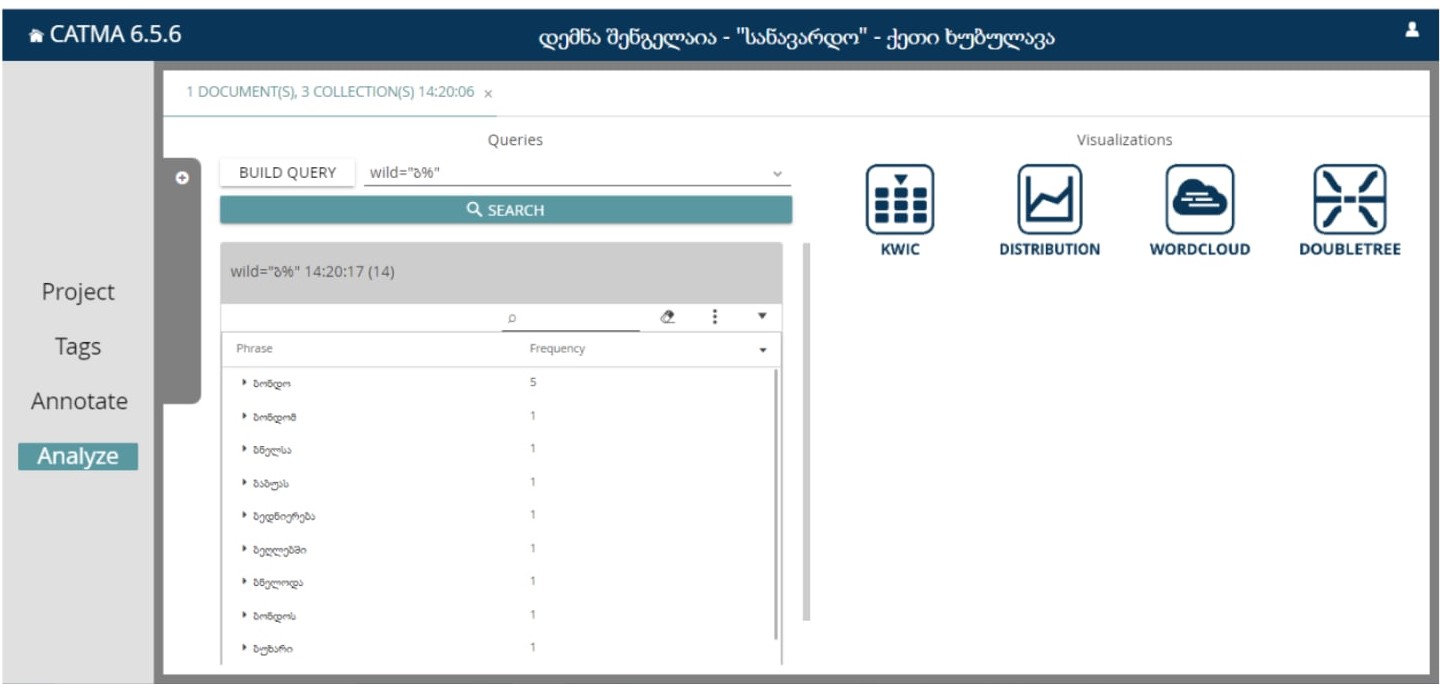
აღნიშნულ გზამკვლევში მოკლედ არის მიმოხილული CATMA-ს ძირითადი, მნიშვნელოვანი ინსტრუმენტები. უფრო დეტალური ანალიზისთვის ან სხვა კითხვების შემთხვევაში, გთხოვთ, მოგვმართეთ.
წყაროები: