")
")
TEI, ანუ „ტექსტის კოდირების ინიცაიტივა“
კომპიუტერს მხოლოდ ისეთი ტექსტის აღქმა შეუძლია, რომელშიც ნიშნები (ანდა ასოები) სპეციალური სისტემით არის წარმოდგენილი. ეს სისტემა დაკავშირებულია ბინარულ სისტემასთან, რომლის ინტერპრეტირებაც კომპიუტერისთვის ადვილია. ამ პროცესს ნიშანთა კოდირება ეწოდება.
ამგვარი კოდირების სხვადასხვა სქემა არსებობს, მაგალითად, ASCII - სტანდარტული ამერიკული კოდი, რომელიც ინფორმაციის მიმოცვლისთვის გამოიყენება. ნიშანთა კოდირების მეშვეობით კომპიუტერებში ტექსტების ბაზები იქმნება და შემდგომ მათი სხვადასხვა პლატფორმაზე გაგზავნაც შეიძლება. თუმცა ნიშანთა კოდირება ტექსტის სემანტიკასთან, მის ინტერპრეტაციასა თუ სტრუქტურასთან კავშირში არაა. ამ უკანასკნელთა ამსახველ მონაცემებს მეტა-ინფორმაციას ვუწოდებთ.
კომპიუტერისთვის ნიშნები უბრალოდ გრაფიკული მონახაზებია, სიტყვების სემანტიკურ მნიშვნელობას ის ვერ აღიქვამს. თუ გვინდა, რომ ტექსტს რაიმე სახის მეტა-ინფორმაცია დავამატოთ, ისე, რომ კომპიუტერმა მისი აღქმა და გამოყენება შეძლოს, ტექსტი უნდა მოვნიშნოთ ან დავშიფროთ, გავწეროთ დამატებითი აღმნიშვნელები და კომპიუტერს ჩვენთვის საჭირო ინფორმაციის ამოცნობა ვასწავლოთ.
ამისათვის, ტექსტს უნდა დავამატოთ რელევანტური ფრაზები ან მათი გამომხატველი კოდები. დაბნეულობის თავიდან ასაცილებლად (რაც გარდაუვალია იმ შემთხვევაში, თუ ყველა მეცნიერი კოდების/აღმნიშვნელთა საკუთარ სისტემას შექმნის), მეცნიერებმა შეიმუშავეს კოდების საერთო სისტემა, რომელიც მოიცავს ყველა ძირითად კოდსა და აღმნიშვნელს, რომლებიც შეიძლება ჰუმანიტარულ სფეროში დაგვჭირდეს. თუმცა, როგორც აღვნიშნეთ, ციფრული ჰუმანიტარია ჯერ კიდევ ვითარდება, ამიტომ თუ რომელიმე მეცნიერს რაიმე ისეთი კოდი დასჭირდება კვლევისთვის, რაც ჯერ არ არის დამატებული ბაზაში, მისი შექმნა და დამატებაც შესაძლებელია.
შინაარსის გამომხატველი კოდი უნდა განსხვავდებოდეს ნიშანთა კოდისგან სპეციალური აღმნიშვნელებით. ერთ-ერთი ასეთი აღმნიშვნელია ტეგი. ტექსტის კოდირებისათვის გამოყენებულ ტეგთა ერთობლიობას აღმნიშვნელთა ენას ვუწოდებთ.
TEI, ანუ „ტექსტის კოდირების ინიციატივა“ არის სტანდარტი, რომელიც კოდირების მეშვეობით ტექსტის ციფრულ ფორმატში წარმოსადგენად გამოიყენება. ეს სტანდარტი შექმნეს TEI კონსორციუმის წევრმა მეცნიერებმა, რომელთა უმეტესობა მოღვაწეობს ჰუმანიტარული და სოციალური მეცნიერებებისა და ლინგვისტიკის სფეროებში.
TEI იყენებს „აღმნიშვნელთა განვრცობად ენას“ – XML-ს, რომელიც სხვადასხვა მექანიზმსა და ინსტრუმენტს გვთავაზობს. ასე რომ, შეგვიძლია, კოდირების მოდელი ჩვენთვის სასურველ პროექტს მოვარგოთ. ამდენად, TEI ერთგვარი გზამკვლევი, ღია, სტანდარტია და იგი შეიძლება, ნებისმიერი ტექსტის კოდირებისთვის გამოვიყენოთ.
XML, იგივე - აღმნიშვნელთა განვრცობადი ენა, პირველად 1998 წელს გამოქვეყნდა და მალევე მოიპოვა პოპულარობა. ეს არის მულტი-ენა, რომელიც ტექსტების TEI სტანდარტით კოდირებისთვის გამოიყენება. XML რამდენიმე კომპონენტისგან შედგება, ესენია:
- ინსტრუქციები
- ელემენტები
- ატრიბუტები
- მითითებები საგნის/აღსანიშნის შესახებ
- (P)CDATA, ანუ ინფორმაცია ნიშნის შესახებ
ელემენტებს შორის მოქცეულია საკვლევი ტექსტი. მაგალითად, ქვემოთ მოცემულ ვერსიაში, <body> და </body> და <p> </p> ელემენტებია და მათ შორის მოქცეულია საკვლევი ტექსტი.
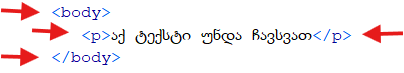
მაგრამ თუ ელემენტებს დავუმატებთ მეტა-ინფორმაციას ტექსტის შესახებ, მაგალითად მოვნიშნავთ მეტაფორას, ან რომელიმე სხვა მხატვრულ ხერხს, მათ აღმნიშვნელ კოდის ნაწილებს უკვე ატრიბუტებს ვუწოდებთ. ატრიბუტი ასე გამოიყურება: source="უცნობია"
ატრიბუტის პირველი ნაწილი გვაწვდის ინფორმაციას აღმნიშვნელზე, ამ შემთხვევაში ფოტოზე მოცემული ატრიბუტი განსაზღვრავს წყაროს. ატრიბუტის ეს ნაწილი მკაცრად განსაზღვრულია და პროგრამა არ მოგვცემს შეუსაბამო ატრიბუტის დამატების საშუალებას. ტოლობის მეორე მხარეს, ბრჭყალებში იწერება მეტა-ინფორმაცია, ამას უკვე თავად მკვლევარი ირჩევს და შეგვიძლია ის ჩავამატოთ, რასაც საჭიროდ ჩავთვლით.
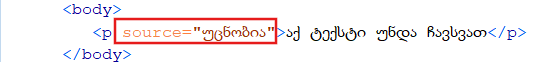
ელემენტის დასაწყისი ყოველთვის უნდა მოვნიშნოთ კუთხოვანი ფრჩხილებით, მაგალითად, ასე: <TEI>, ხოლო დასასრული პირველი ფრჩხილის შემდგომ დახრილი ხაზით - </TEI>. ელემენტის ორივე კომპონენტი - დასაწყისიც და დასასრულიც აუცილებელია, თუ რომელიმეს გამოვტოვებთ, კოდი სწორი არ იქნება.
მეორე მხრივ, ატრიბუტს აუცილებლად სჭირდება =-ის ნიშანი და ბრჭყალები ("...").
პროზაული ტექსტისა და პოეტური ლექსის კოდირება მეტ-ნაკლებად განსხვავდება თითოეულის სპეციფიკიდან გამომდინარე.